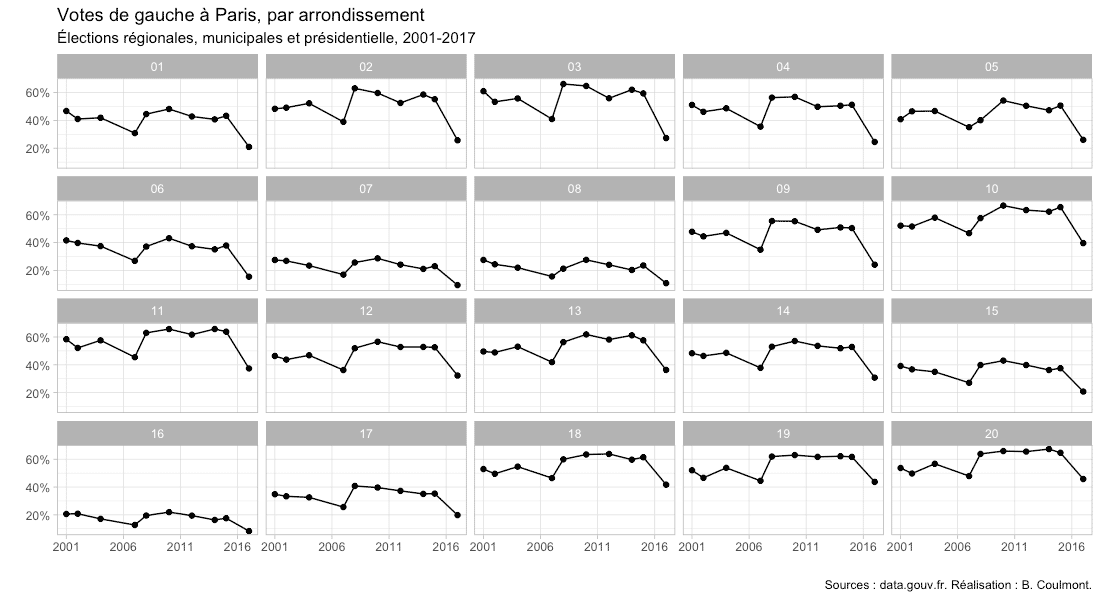
Les dessous d’une carte
Qu’ai-je du faire pour tracer cette carte, que l’on trouve dans le billet écrit avec Lucie Bargel et intitulé « À la campagne, la victoire est en ville », sur le blog Terrains de campagne

D’abord, que représente-t-elle ? Les zones où il y a plus d’inscrit.e.s sur les listes électorales que de résident.e.s français.es majeur.e.s.
Il faut d’abord récupérer les résultats électoraux à l’échelle des communes. Par exemple, les résultats de la présidentielle de 2012. Ces listes indiquent, pour chaque commune, combien il y a d’inscrits sur les listes, ce qui est essentiel pour pouvoir calculer, par exemple, un taux d’abstention.
Il faut ensuite récupérer les Fichiers détails du recensement 2012 (fichier « individus localisés au canton-ou-ville »), car ces fichiers permettent de sélectionner les Français majeurs (les individus recensés, de nationalité française, et âgés de 18 ans ou plus en 2012). Les résultats du recensement agrégés à l’échelle des communes, que l’on trouve facilement sans avoir de calcul à faire n’indiquent pas si les personnes majeures sont de nationalité française.
Et on rapproche les deux bases : Inscrits et Résidents.
Mais : la géographie du recensement de l’année N est celle de l’année N+2. Par exemple, si la commune de Triffoulli a été fusionnée avec la commune des Oies en 2012 ou 2013, les résultats du recensement sont diffusés pour la nouvelle commune de Triffoulli – Les Oies.
Il faut donc faire passer la base Inscrits de la géographie 2012 à la géographie 2014.
De plus, les résultats du recensement sont diffusés non pas toujours à l’échelle des communes, mais à celle du “Canton-ou-Ville” (à la géographie N+2). Il faut donc associer à chaque commune du fichier des Inscrits le Canton-ou-Ville dans lequel elle se trouve.
Et là, on peut faire la jointure des deux bases et calculer un ratio Inscrits/Résidents-français-majeurs.
Et ça ne suffit pas : il faut aussi transformer le fonds de carte “Geofla communes” (2014) en fusionnant les polygones des communes qui appartiennent aux mêmes “cantons-ou-villes”. Maintenant, on peut associer le ratio calculé précédemment à la carte.
La carte que l’on ferait pour l’année 2012 révèlerait une géographie intéressante. La sur-inscription est fréquente dans les petites villes de plateau et de montagne, et dans une série de villages du littoral. Mais… les enquêtes annuelles de recensement ont lieu tous les cinq ans, avec une méthode particulière pour les petites villes. Est-ce que la carte ne serait pas une illusion ?
C’est pour cela que j’ai souhaité m’assurer de la stabilité de cette géographie sur plusieurs années, plusieurs recensements, des élections différentes. La distribution géographique est stable. Il reste à l’analyser.
Pour aller plus loin : « À la campagne, la victoire est en ville », sur le blog Terrains de campagne





 Vous parcourez peut-être ces lignes parce que vous venez de lire ma chronique publiée dans Le Monde, dans le cahier « Science & Médecine » du mercredi 5 décembre 2018, et que vous avez voulu en savoir un peu plus ?
Vous parcourez peut-être ces lignes parce que vous venez de lire ma chronique publiée dans Le Monde, dans le cahier « Science & Médecine » du mercredi 5 décembre 2018, et que vous avez voulu en savoir un peu plus ?






 Depuis quelques années, toutes les six semaines, je rédige une chronique sociologique pour Le Monde. En 2015, j’avais déjà proposé
Depuis quelques années, toutes les six semaines, je rédige une chronique sociologique pour Le Monde. En 2015, j’avais déjà proposé 


 En 2008, Céline Béraud et moi avions écrit un manuel d’introduction, à destination des licences de sociologie, Les courants contemporains de la sociologie (Presses universitaires de France). Après dix ans dans les librairies, la première édition n’est actuellement plus disponible. Mais à la rentrée, c’est une nouvelle édition remaniée qui sera mise en vente, toujours aux Presses universitaires de France, mais dans la collection Quadrige – Manuels. Nous venons de rendre le manuscrit.
En 2008, Céline Béraud et moi avions écrit un manuel d’introduction, à destination des licences de sociologie, Les courants contemporains de la sociologie (Presses universitaires de France). Après dix ans dans les librairies, la première édition n’est actuellement plus disponible. Mais à la rentrée, c’est une nouvelle édition remaniée qui sera mise en vente, toujours aux Presses universitaires de France, mais dans la collection Quadrige – Manuels. Nous venons de rendre le manuscrit.




