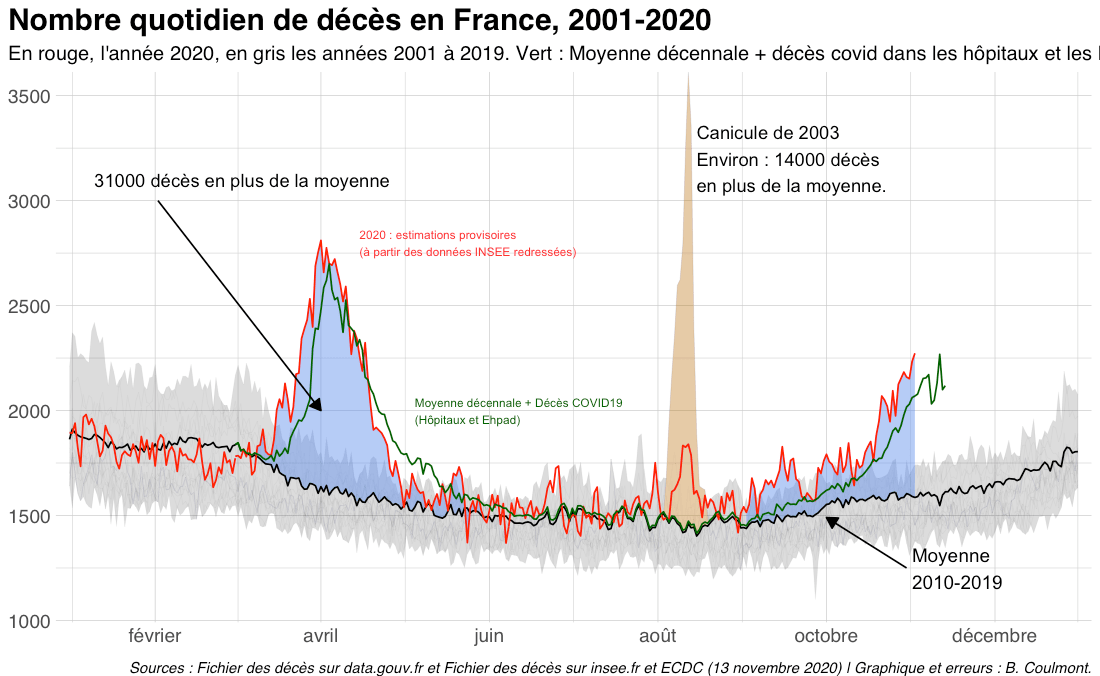
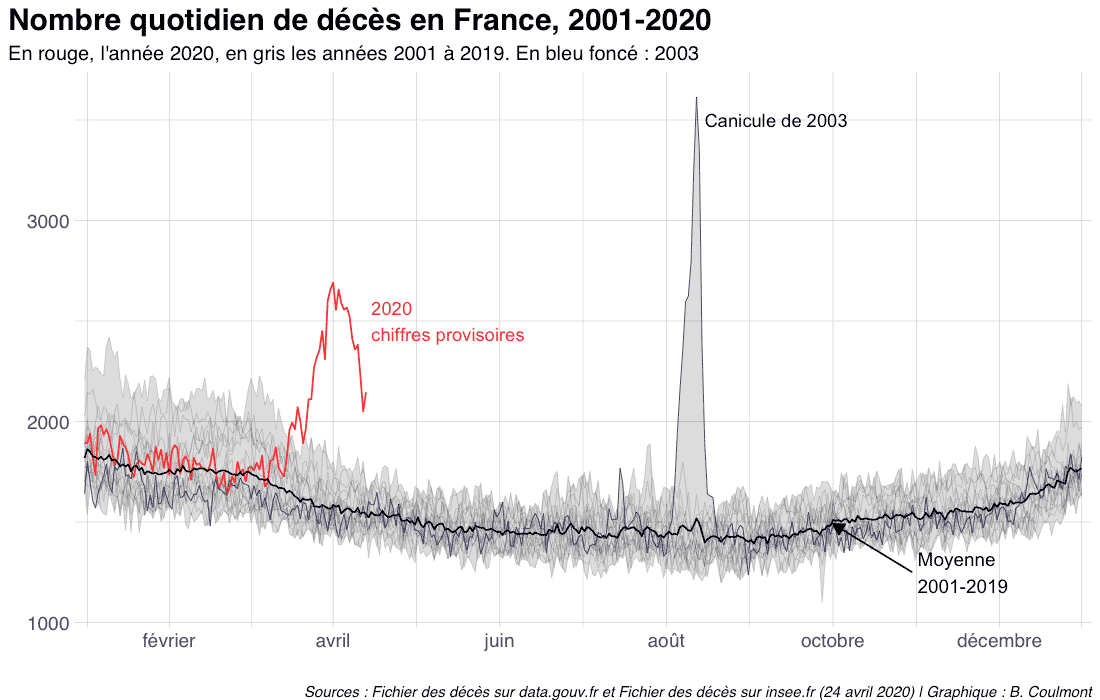
Un prénom pour la vie (et aussi pour la mort)
Le Fichier des prénoms donne le nombre annuel de bébés ayant reçu tel ou tel prénom. Le Fichier des personnes décédées donne le nom, le prénom, la date de naissance et la date de décès des personnes décédées. Mettons-les en relation et regardons si tout le monde meurt au même rythme.
Mais le Fichier des personnes décédées ne nous donne pas les décès avant 1970. Examinons-donc la génération 1970. Je prends les 14 prénoms masculins et les 14 prénoms féminins les plus donnés cette année-là et, année après année, je compte les morts. Fin 2024, plus de 9% des Franck de 1970 sont déjà décédés. À comparer avec 3,8% des Florence. Les Florence (de 1970) décèdent moins vite : peut-être parce qu’elles sont à la fois femmes et plus souvent d’une origine sociale élevée. Les Franck de 1970, eux, meurent peut-être comme des hommes de classes populaires, plus vite que tout le monde.

Le graphique précédent a été composé en rapprochant deux bases qui, si elles sont toutes deux produites par l’Insee, n’ont pas la même origine. Le Fichier des personnes décédées n’est peut-être pas entièrement exhaustif pour le début des années 1970… Ne tenez donc pas compte de micro-différences, qui sont peut-être le produit d’erreurs.
Le code R ayant servi à produire le graphique est disponible sur github (en version brouillon, à vous de l’adapter).