Quinze ans de procurations à Paris, 2007-2022
La carte ci-dessous représente la proportion des voix exprimées qui sont des votes par procuration, à Paris, par bureau de vote, pour les élections municipales, législatives et présidentielles, de 2007 à 2022.
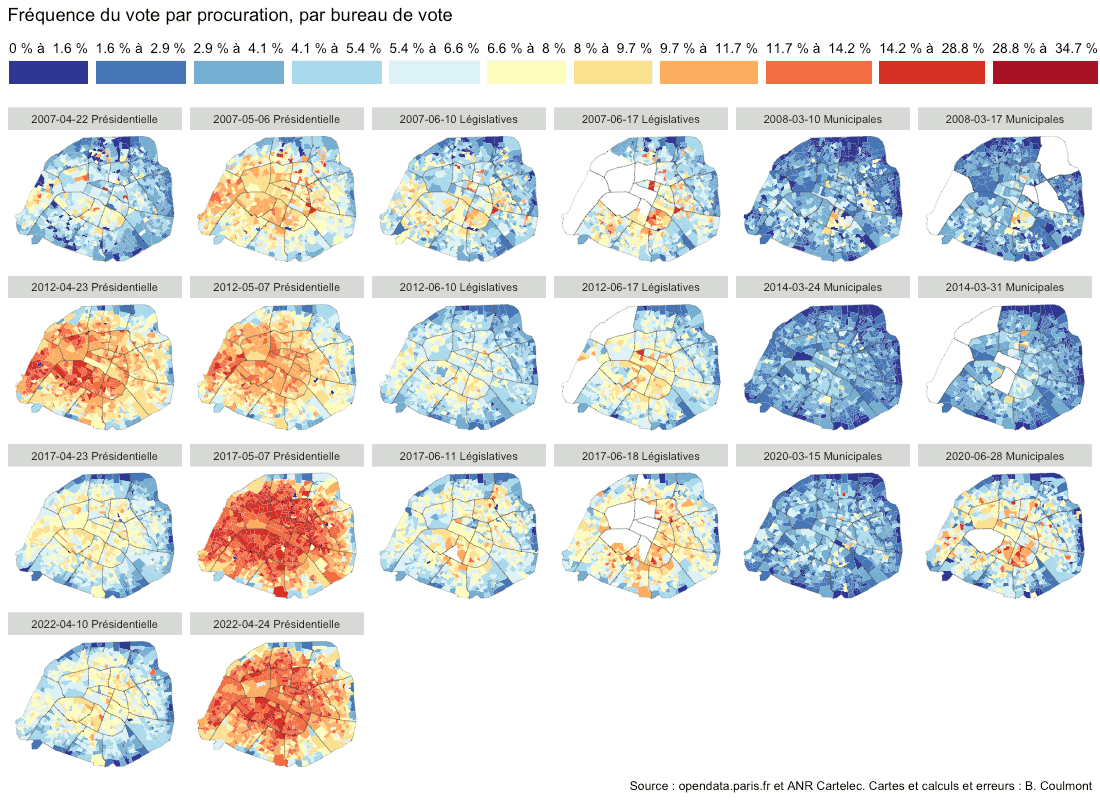
cliquez pour agrandir
On retrouve des régularités : (1) le vote par procuration est plus fréquent en période de vacances scolaires ou de «pont» (et donc au moment des présidentielles, qui ont lieu pendant les vacances de printemps), (2) le vote par procuration est plus fréquent dans les beaux quartiers que dans la ceinture de logements sociaux situés à proximité du périphérique, et (3) le vote par procuration, lors des municipales, est plus fréquent là où le résultat de l’élection est incertain (mais ce point, je devrais le vérifier).
Si l’on calcule la fréquence moyenne, sur ces vingt scrutins, du vote par procuration, on peut tracer la carte suivante :

Comme les frontières des bureaux de vote ont changé entre 2007 et 2022, j’ai découpé Paris en petits carrés et estimé la fréquence qu’on aurait si les bureaux de vote étaient ces petits carrés.