Charlie marqueur événementiel
La fréquence des prénoms est-elle sensible aux événements ?
En 1915, le général Joffre, perçu comme un héros militaire suite aux premières victoires françaises, inspira des parents. Il naquit quelques Joffrette, que la presse — patriotique en ces temps de guerre — célébra. Des réchauds à gaz et des biscuits furent aussi baptisés Joffrette et Joffrinette : l’imagination des publicitaires est sans limite.

Balzac, qui tend parfois à expliquer l’origine des prénoms de ses personnages, indique ainsi [Beatrix, C.H., Tome 2, p.651] qu’un certain Calyste, né “le jour même de l’entrée de Louis XVIII à Calais”, reçu alors aussi le prénom de Louis.
Bref : les prénoms sont parfois choisis en hommage. Rien de nouveau. Rien d’étrange alors à que qu’un prénom comme Mazarine ou Barack, [quasi-]inconnus respectivement en France avant 1995 et aux Etats-Unis avant 2007, ne connaissent un petit succès, qui en 1996, qui en 2008-2009.
Et inversement, d’autres événements vont faire chuter certains prénoms. Les parents étatsuniens cessent de donner Hillary en 1992-1993, quand William J. “Bill” Clinton devient président et sa femme, Hillary Rodham, “First Lady”. De même Katrina connaît une chute brutale après le passage de l’ouragan du même nom en 2005-2006.

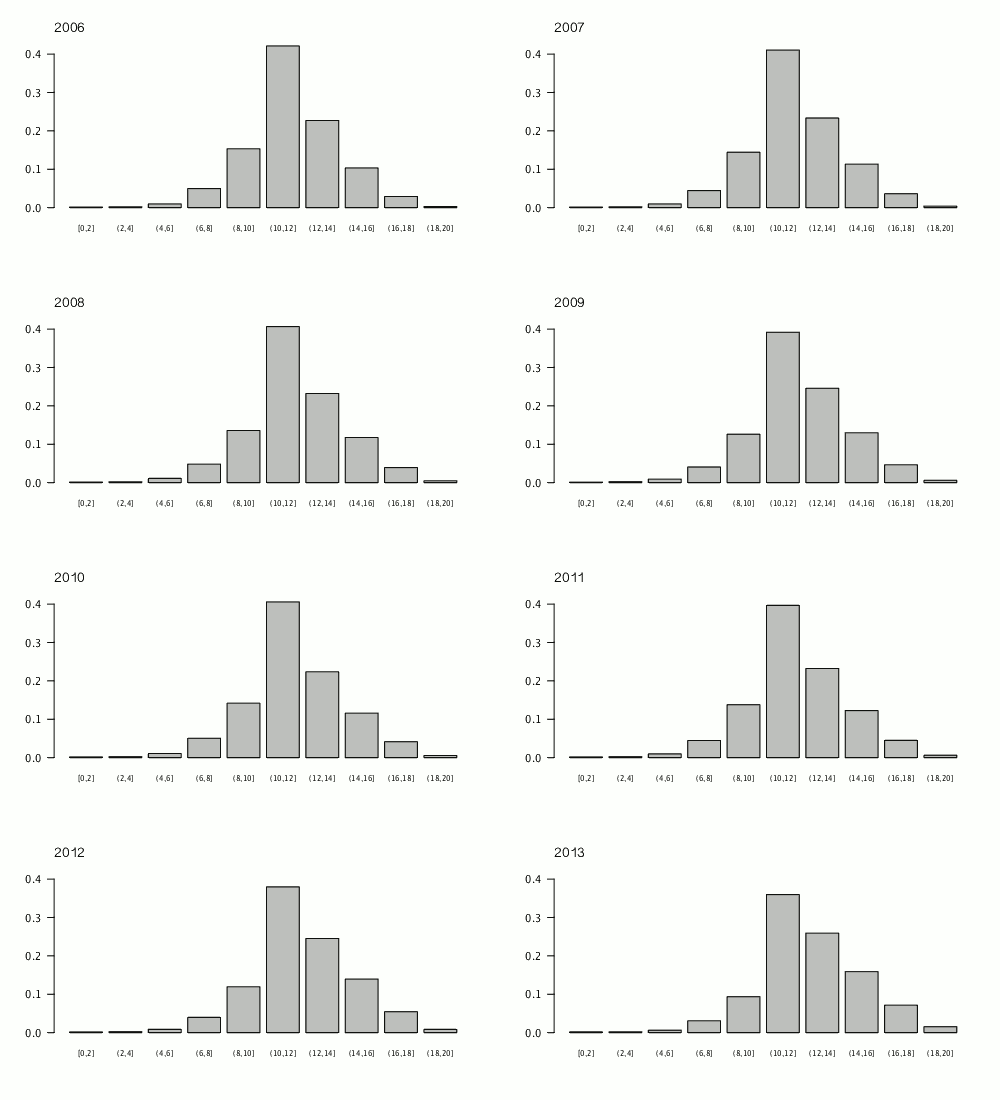
Que va-t-il se passer avec le prénom “Charlie” ? Il était, depuis une dizaine d’années, en forte croissance, à la fois comme prénom de garçon et comme prénom de fille. Les parents vont-ils continuer à le donner de plus en plus, ou vont-il cesser de le faire en raison de l’association avec les attentats du 7 janvier : on trouve déjà des “Charly” qui disposent maintenant d’une nouvelle connotation : leur prénom “dit quelque chose” (mais quoi?). Si quelques témoignages ou les premiers éléments permettent de repérer en une dizaine de jours une vingtaine de bébés Charlie dans les “Carnets” de la presse quotidienne, ce n’est peut-être qu’un feu de paille.
Mais dès 1915, les stratégies parentales d’hommages s’accommodent de la multiplicité des prénoms. Un entrefilet dans La Croix le remarque :

De très nombreux bébés naissent en France avec plusieurs prénoms, des seconds prénoms invisibles dont on a beaucoup de mal à se souvenir (que celles et ceux qui connaissent les seconds prénoms de leurs cousins et cousines lèvent la main). Ces seconds prénoms servent aux hommages familiaux — et ce d’autant plus que l’arrière-grand mère avait un “joli” prénom. Ils servent de réceptacles aux prénoms démodés des parrains — parfois, quand l’enfant est baptisé. Ils servent de tiroir aux prénoms sur lesquels le consensus ne s’est pas fait. Ils servent aussi, dans le cas présent, d’hommage indélébile mais invisible :
Prénom Charlie : pic d’attribution en 2e et 3e choix à Paris [Elodie Moreau] (…)
Si, pour l’heure, on ne note pas d’ « effet Charlie » sur l’ensemble du territoire, la capitale fait exception en la matière. Davantage de jeunes parents parisiens ont en effet choisi Charlie en 2e ou 3e prénom pour leur enfant. « C’est une nouveauté », nous confirme la mairie de Paris. Depuis mercredi dernier, ce prénom a été attribué 11 fois en 2ème ou 3ème position sur près de 670 naissances.
ou encore :
«Charlie» se glisse dans les berceaux des maternités [Aline Gérard]
« On s’en est aperçu lors de la déclaration de naissance d’un petit garçon né le 10 janvier. Ses parents lui avaient donné comme troisième prénom Charlie. D’habitude, les couples choisissent comme deuxième ou troisième prénom celui d’un ascendant ou d’un parrain. Mais là, il n’y avait aucun Charlie ni dans la généalogie, ni dans l’entourage », raconte un agent des services de l’état civil de la mairie du XIIIe arrondissement de Paris.
« Ces parents placent Charlie généralement en troisième ou quatrième position », précise-t-on à la mairie du XVe où, là aussi, on a repéré le phénomène. « En quelques jours, on a vu passer une petite dizaine de déclarations de ce type, qu’il s’agisse de garçons ou de filles », constate, de son côté, la mairie du XIIe arrondissement.
L’hommage onomastique passera donc peut-être, en janvier-février 2015, par la multiplication des “Charlie” en deuxième position : un marquage conjugal / familial du moment de la naissance, marquage invisible aux yeux de presque tous, mais marquage permanent. Le prénom inscrit aujourd’hui les personnes dans des générations, des classes d’âge. Il peut aussi marquer le moment, l’événement (la conjonction de l’événement parental et de l’événement politique).