La vie associative à Nantes (1)
Le site open-data de Nantes, data.nantes.fr, est riche. On y trouve : un fond de carte des “quartiers”, un fond de carte des “bureaux de vote”, la liste (avec les adresses) des associations, et enfin un fichier avec la géolocalisation de chaque adresse postale. En combinant ces fichiers, il est possible de repérer dans quels “microquartiers” la vie associative est plus développée, ou, au moins là où les associations sont implantées.
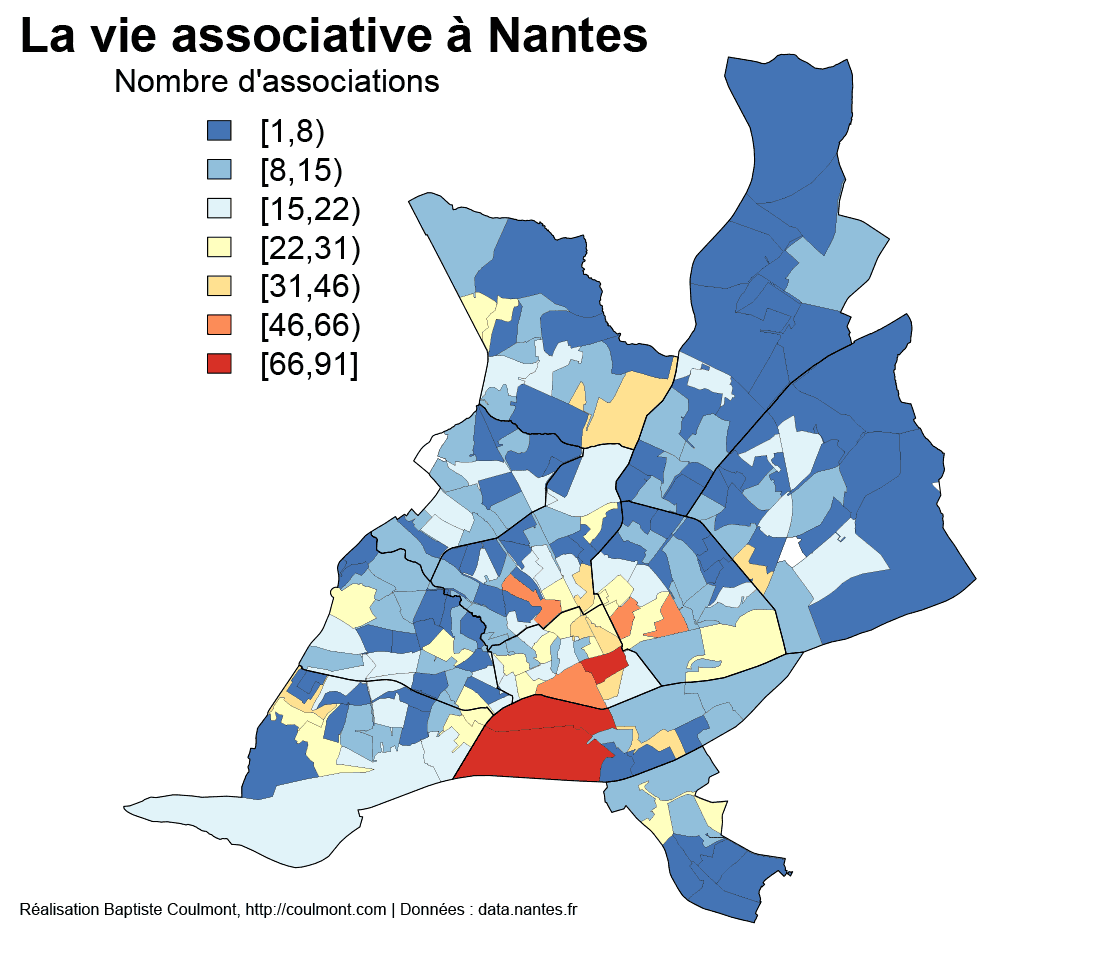
Les Nantais ou les spécialistes de la Sociologie de Nantes comprendront sans doute mieux que moi la logique des implantations.
La réalisation a consister à assigner à chaque adresse de Nantes le nombre d’associations qui y avaient élu domicile (pas leur siège, mais leur lieu d’activité), et ensuite à associer à chaque adresse un “bureau de vote” correspondant, et enfin à associer à chaque bureau de vote le nombre d’associations qui se trouvaient dans son ressort.
Voici le code R :
library(maptools) library(sp) library(RColorBrewer) library(classInt) # shapefile des quartiers de Nantes # Charger le fichier des adresses adresses<-readShapeSpatial("~/Desktop/nantes/ADRESSES_NM_shp_l93/ADRESSES_NM.shp") adresses<-subset(adresses,adresses$NOMCOM=="NANTES") adresses$ADRESSE<-iconv(adresses$ADRESSE,from="latin1",to="ASCII//TRANSLIT") adresses$ADRESSE<-toupper(adresses$ADRESSE) # Charger le fichier associations associations <- read.csv("~/Desktop/nantes/nantes-associations.csv",header=T) # charger le shapefile des bureaux de vote de Nantes nantesbv<-readShapeSpatial("~/Desktop/nantes/DECOUPAGE_BUREAUX_VOTE_NANTES_shp_l93/DECOUPAGE_BUREAUX_VOTE_NANTES.shp") assoces<-associations[,c("SIEGE_NUM","SIEGE_VOIE","LIEU_ACT_NUM","LIEU_ACT_VOIE","LIB_THEME")] assoces$SIEGE<-paste(assoces$SIEGE_NUM,assoces$SIEGE_VOIE) assoces$LIEU<-paste(assoces$LIEU_ACT_NUM,assoces$LIEU_ACT_VOIE) assoces$SIEGE<-iconv(assoces$SIEGE,from="UTF-8",to="ASCII//TRANSLIT") assoces$LIEU<-iconv(assoces$LIEU,from="UTF-8",to="ASCII//TRANSLIT") assoces$SIEGE<-toupper(assoces$SIEGE) assoces$LIEU<-toupper(assoces$LIEU) assoces$NB<-1 #assoces_adresses<-aggregate(NB~SIEGE,data=assoces,sum) assoces_adresses<-aggregate(NB~LIEU,data=assoces,sum) # associer les adresses des associations avec leurs coordonnées #m<-match(adresses$ADRESSE,assoces_adresses$SIEGE) m<-match(adresses$ADRESSE,assoces_adresses$LIEU) adresses$NB<-assoces_adresses$NB[m] # nantesbv : bureaux de votes de nantes # associer chaque adresse à un bureau de vote # code non optimal : boucle "for" très lente BV<-NULL test2<-NULL for (i in 1:nrow(adresses)){ for (j in 1:nrow(nantesbv)) { ifelse(point.in.polygon(adresses@coords[[i,1]],adresses@coords[[i,2]],nantesbv@polygons[[j]]@Polygons[[1]]@coords[,1],nantesbv@polygons[[j]]@Polygons[[1]]@coords[,2])==1,BV[i]<-j,test2<-j) } } adresses$BV<-nantesbv$IDBURO[BV] assoc_bv<-aggregate(NB~BV,data=adresses,sum) m<-match(nantesbv$IDBURO,assoc_bv$BV) nantesbv$NB<-assoc_bv$NB[m] nclr <- 7 plotclr <- brewer.pal(nclr,"RdYlBu")[nclr:1] class <- classIntervals(nantesbv$NB, nclr, style="fisher",dataPrecision=0) colcode <- findColours(class, plotclr) par(mar=c(1,1,1,1)) plot(nantesbv,col=colcode,border="black",lwd=.1) legend(348479,6698193,legend=names(attr(colcode,"table")), fill=attr(colcode, "palette"), cex=2, bty="n",title="Nombre d'associations") plot(quartiers,add=T) title(sub="Réalisation Baptiste Coulmont, https://coulmont.com | Données : data.nantes.fr",cex.sub=1,adj=0,line=-3) title(main="La vie associative à Nantes",line=-1.7,cex.main=3,adj=0)