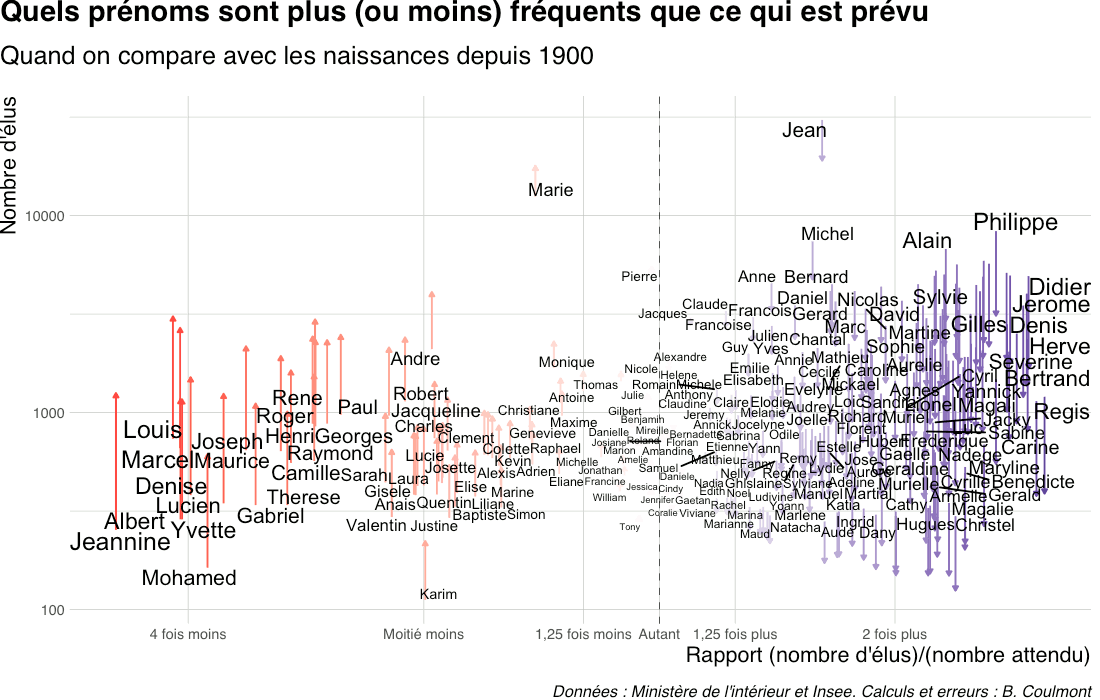
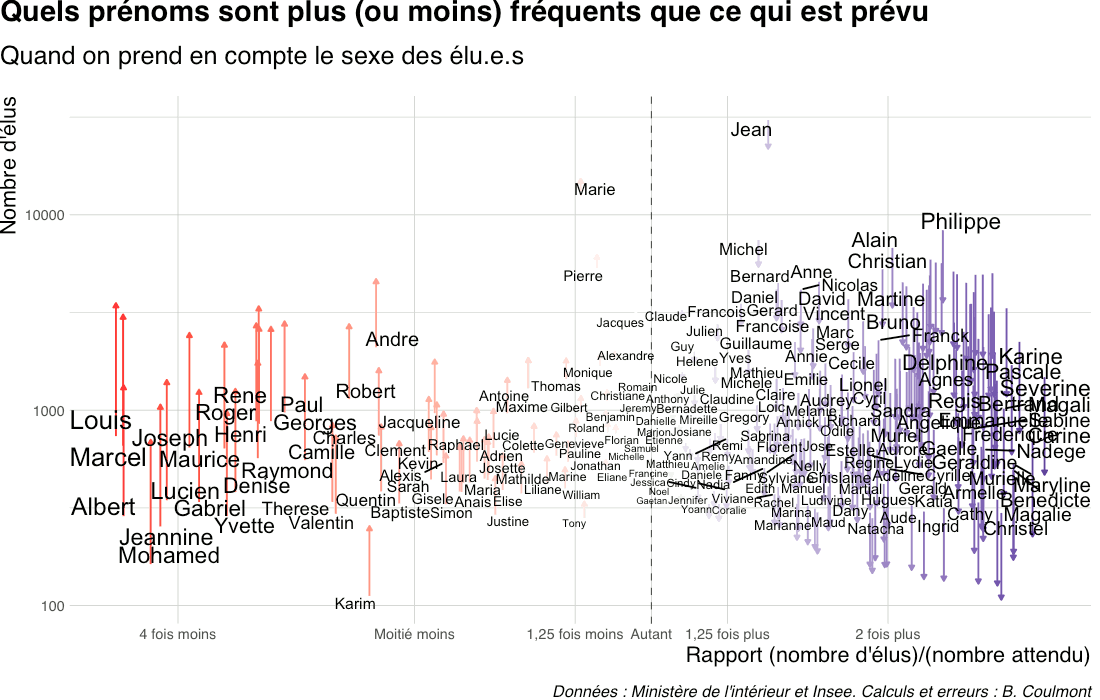
Docteur Kevin
Les “épreuves classantes nationales” sont l’examen qui précède, pour les étudiants et étudiantes en médecine, le choix de spécialité et d’internat. Jusqu’en 2023, la liste nominative des personnes reçues, ainsi que leur rang de classement, étaient publiées au Journal officiel.
En comparant cette liste avec les prénoms des bébés nés environ 24 ans plus tôt, il est possible d’estimer quelle proportion de Marie ou de Maxime a fini par devenir médecin – en faisant l’hypothèse que tous ces médecins sont nés en France.
Sur la période 2014-2023, le nombre de personnes classées aux épreuves est d’environ 8 à 9 000. Et il y a, pour les années 1990 à 1999, environ 770 000 naissances par an. Ce qui fait qu’environ 1,1 à 1,3% des bébés finissent par devenir médecins.
Je compare le nombre de candidats reçus au nombre de naissances (pour la période correspondant en gros aux années de naissance des candidats).
Je n’ai gardé que les prénoms donnés plus de 5000 fois sur 10 ans (soit plus de 500 naissances par an en moyenne).
Pour les filles, et pour ces prénoms, Anne est le plus “médecin”, car 4,2% des bébés Anne sont devenues médecin (au sens de “reçue aux épreuves classantes nationales”)… et tout en bas du tableau, vous trouverez Alison : seulement 3 Alison sur 1000 deviennent médecin.
| prenom | sexe | ecn | naissances | combien | comparaison |
|---|---|---|---|---|---|
| Anne | F | 326 | 7673 | 4.2 Anne sur 100 naissances | référence |
| Jeanne | F | 281 | 8778 | 3.2 Jeanne sur 100 naissances | 1.3 fois moins que Anne |
| Anna | F | 189 | 5956 | 3.2 Anna sur 100 naissances | 1.3 fois moins que Anne |
| Constance | F | 160 | 5408 | 3 Constance sur 100 naissances | 1.4 fois moins que Anne |
| Agathe | F | 316 | 10726 | 2.9 Agathe sur 100 naissances | 1.4 fois moins que Anne |
| Aude | F | 168 | 5755 | 2.9 Aude sur 100 naissances | 1.5 fois moins que Anne |
| Alice | F | 539 | 18693 | 2.9 Alice sur 100 naissances | 1.5 fois moins que Anne |
| Juliette | F | 584 | 20471 | 2.9 Juliette sur 100 naissances | 1.5 fois moins que Anne |
| Louise | F | 422 | 14836 | 2.8 Louise sur 100 naissances | 1.5 fois moins que Anne |
| Clemence | F | 555 | 20874 | 2.7 Clemence sur 100 naissances | 1.6 fois moins que Anne |
| Claire | F | 694 | 26222 | 2.6 Claire sur 100 naissances | 1.6 fois moins que Anne |
| Helene | F | 368 | 14047 | 2.6 Helene sur 100 naissances | 1.6 fois moins que Anne |
| Sara | F | 131 | 5011 | 2.6 Sara sur 100 naissances | 1.6 fois moins que Anne |
| Clementine | F | 224 | 8626 | 2.6 Clementine sur 100 naissances | 1.6 fois moins que Anne |
| Lise | F | 136 | 5273 | 2.6 Lise sur 100 naissances | 1.6 fois moins que Anne |
| Cecile | F | 329 | 13536 | 2.4 Cecile sur 100 naissances | 1.7 fois moins que Anne |
| Clara | F | 452 | 19111 | 2.4 Clara sur 100 naissances | 1.8 fois moins que Anne |
| Elise | F | 369 | 15615 | 2.4 Elise sur 100 naissances | 1.8 fois moins que Anne |
| Heloise | F | 123 | 5391 | 2.3 Heloise sur 100 naissances | 1.9 fois moins que Anne |
| Mathilde | F | 993 | 44356 | 2.2 Mathilde sur 100 naissances | 1.9 fois moins que Anne |
| Laure | F | 237 | 10596 | 2.2 Laure sur 100 naissances | 1.9 fois moins que Anne |
| Marie | F | 1554 | 69742 | 2.2 Marie sur 100 naissances | 1.9 fois moins que Anne |
| Valentine | F | 218 | 10106 | 2.2 Valentine sur 100 naissances | 2 fois moins que Anne |
| Anne-Sophie | F | 128 | 5943 | 2.2 Anne-Sophie sur 100 naissances | 2 fois moins que Anne |
| Elsa | F | 166 | 7739 | 2.1 Elsa sur 100 naissances | 2 fois moins que Anne |
| Lucile | F | 200 | 9373 | 2.1 Lucile sur 100 naissances | 2 fois moins que Anne |
| Solene | F | 246 | 11566 | 2.1 Solene sur 100 naissances | 2 fois moins que Anne |
| Maud | F | 140 | 6603 | 2.1 Maud sur 100 naissances | 2 fois moins que Anne |
| Camille | F | 1422 | 67174 | 2.1 Camille sur 100 naissances | 2 fois moins que Anne |
| Ines | F | 342 | 16371 | 2.1 Ines sur 100 naissances | 2 fois moins que Anne |
| Salome | F | 132 | 6351 | 2.1 Salome sur 100 naissances | 2 fois moins que Anne |
| Sophie | F | 465 | 22508 | 2.1 Sophie sur 100 naissances | 2.1 fois moins que Anne |
| Charlotte | F | 701 | 34032 | 2.1 Charlotte sur 100 naissances | 2.1 fois moins que Anne |
| Caroline | F | 450 | 22280 | 2 Caroline sur 100 naissances | 2.1 fois moins que Anne |
| Margaux | F | 455 | 22771 | 2 Margaux sur 100 naissances | 2.1 fois moins que Anne |
| Emma | F | 366 | 18448 | 2 Emma sur 100 naissances | 2.1 fois moins que Anne |
| Julia | F | 201 | 10189 | 2 Julia sur 100 naissances | 2.2 fois moins que Anne |
| Roxane | F | 98 | 5033 | 1.9 Roxane sur 100 naissances | 2.2 fois moins que Anne |
| Pauline | F | 1012 | 56166 | 1.8 Pauline sur 100 naissances | 2.4 fois moins que Anne |
| Perrine | F | 112 | 6269 | 1.8 Perrine sur 100 naissances | 2.4 fois moins que Anne |
| Margot | F | 237 | 13441 | 1.8 Margot sur 100 naissances | 2.4 fois moins que Anne |
| Zoe | F | 100 | 5706 | 1.8 Zoe sur 100 naissances | 2.4 fois moins que Anne |
| Marion | F | 902 | 51670 | 1.7 Marion sur 100 naissances | 2.4 fois moins que Anne |
| Coline | F | 120 | 6977 | 1.7 Coline sur 100 naissances | 2.5 fois moins que Anne |
| Anaelle | F | 95 | 5641 | 1.7 Anaelle sur 100 naissances | 2.5 fois moins que Anne |
| Lena | F | 94 | 5660 | 1.7 Lena sur 100 naissances | 2.6 fois moins que Anne |
| Maelle | F | 101 | 6093 | 1.7 Maelle sur 100 naissances | 2.6 fois moins que Anne |
| Chloe | F | 719 | 43380 | 1.7 Chloe sur 100 naissances | 2.6 fois moins que Anne |
| Lucie | F | 540 | 32750 | 1.6 Lucie sur 100 naissances | 2.6 fois moins que Anne |
| Lauriane | F | 87 | 5355 | 1.6 Lauriane sur 100 naissances | 2.6 fois moins que Anne |
| Emmanuelle | F | 119 | 7382 | 1.6 Emmanuelle sur 100 naissances | 2.6 fois moins que Anne |
| Tiphaine | F | 99 | 6143 | 1.6 Tiphaine sur 100 naissances | 2.6 fois moins que Anne |
| Clarisse | F | 89 | 5701 | 1.6 Clarisse sur 100 naissances | 2.7 fois moins que Anne |
| Delphine | F | 139 | 9240 | 1.5 Delphine sur 100 naissances | 2.8 fois moins que Anne |
| Axelle | F | 102 | 6870 | 1.5 Axelle sur 100 naissances | 2.9 fois moins que Anne |
| Sarah | F | 708 | 50418 | 1.4 Sarah sur 100 naissances | 3 fois moins que Anne |
| Floriane | F | 118 | 8405 | 1.4 Floriane sur 100 naissances | 3 fois moins que Anne |
| Fanny | F | 314 | 22374 | 1.4 Fanny sur 100 naissances | 3 fois moins que Anne |
| Eloise | F | 97 | 6925 | 1.4 Eloise sur 100 naissances | 3 fois moins que Anne |
| Julie | F | 798 | 57364 | 1.4 Julie sur 100 naissances | 3.1 fois moins que Anne |
| Lea | F | 714 | 52339 | 1.4 Lea sur 100 naissances | 3.1 fois moins que Anne |
| Victoria | F | 136 | 10049 | 1.4 Victoria sur 100 naissances | 3.1 fois moins que Anne |
| Lisa | F | 251 | 18617 | 1.3 Lisa sur 100 naissances | 3.2 fois moins que Anne |
| Romane | F | 130 | 9779 | 1.3 Romane sur 100 naissances | 3.2 fois moins que Anne |
| Celine | F | 313 | 24172 | 1.3 Celine sur 100 naissances | 3.3 fois moins que Anne |
| Elisa | F | 149 | 11529 | 1.3 Elisa sur 100 naissances | 3.3 fois moins que Anne |
| Estelle | F | 250 | 19369 | 1.3 Estelle sur 100 naissances | 3.3 fois moins que Anne |
| Carla | F | 67 | 5320 | 1.3 Carla sur 100 naissances | 3.4 fois moins que Anne |
| Gaelle | F | 123 | 9772 | 1.3 Gaelle sur 100 naissances | 3.4 fois moins que Anne |
| Aurore | F | 179 | 14410 | 1.2 Aurore sur 100 naissances | 3.4 fois moins que Anne |
| Alexandra | F | 232 | 18689 | 1.2 Alexandra sur 100 naissances | 3.4 fois moins que Anne |
| Nina | F | 75 | 6063 | 1.2 Nina sur 100 naissances | 3.4 fois moins que Anne |
| Eva | F | 167 | 13563 | 1.2 Eva sur 100 naissances | 3.5 fois moins que Anne |
| Marine | F | 784 | 64154 | 1.2 Marine sur 100 naissances | 3.5 fois moins que Anne |
| Noemie | F | 237 | 19656 | 1.2 Noemie sur 100 naissances | 3.5 fois moins que Anne |
| Myriam | F | 124 | 10390 | 1.2 Myriam sur 100 naissances | 3.6 fois moins que Anne |
| Aline | F | 73 | 6140 | 1.2 Aline sur 100 naissances | 3.6 fois moins que Anne |
| Jade | F | 87 | 7565 | 1.2 Jade sur 100 naissances | 3.7 fois moins que Anne |
| Amelie | F | 302 | 26359 | 1.1 Amelie sur 100 naissances | 3.7 fois moins que Anne |
| Florine | F | 59 | 5224 | 1.1 Florine sur 100 naissances | 3.8 fois moins que Anne |
| Justine | F | 453 | 40379 | 1.1 Justine sur 100 naissances | 3.8 fois moins que Anne |
| Audrey | F | 370 | 33283 | 1.1 Audrey sur 100 naissances | 3.8 fois moins que Anne |
| Lola | F | 71 | 6440 | 1.1 Lola sur 100 naissances | 3.9 fois moins que Anne |
| Leila | F | 62 | 5695 | 1.1 Leila sur 100 naissances | 3.9 fois moins que Anne |
| Sonia | F | 101 | 9278 | 1.1 Sonia sur 100 naissances | 3.9 fois moins que Anne |
| Celia | F | 157 | 14444 | 1.1 Celia sur 100 naissances | 3.9 fois moins que Anne |
| Olivia | F | 75 | 7059 | 1.1 Olivia sur 100 naissances | 4 fois moins que Anne |
| Christelle | F | 57 | 5388 | 1.1 Christelle sur 100 naissances | 4 fois moins que Anne |
| Manon | F | 669 | 63286 | 1.1 Manon sur 100 naissances | 4 fois moins que Anne |
| Emilie | F | 366 | 34969 | 1 Emilie sur 100 naissances | 4.1 fois moins que Anne |
| Charline | F | 87 | 8372 | 1 Charline sur 100 naissances | 4.1 fois moins que Anne |
| Alexia | F | 144 | 14835 | 1 Alexia sur 100 naissances | 4.4 fois moins que Anne |
| Laurine | F | 98 | 10453 | 0.9 Laurine sur 100 naissances | 4.5 fois moins que Anne |
| Aurelie | F | 270 | 29103 | 0.9 Aurelie sur 100 naissances | 4.6 fois moins que Anne |
| Virginie | F | 85 | 9618 | 0.9 Virginie sur 100 naissances | 4.8 fois moins que Anne |
| Morgane | F | 301 | 34321 | 0.9 Morgane sur 100 naissances | 4.8 fois moins que Anne |
| Mylene | F | 50 | 5747 | 0.9 Mylene sur 100 naissances | 4.9 fois moins que Anne |
| Laura | F | 596 | 70015 | 0.9 Laura sur 100 naissances | 5 fois moins que Anne |
| Anissa | F | 50 | 5914 | 0.8 Anissa sur 100 naissances | 5 fois moins que Anne |
| Marjorie | F | 57 | 6860 | 0.8 Marjorie sur 100 naissances | 5.1 fois moins que Anne |
| Johanna | F | 85 | 10313 | 0.8 Johanna sur 100 naissances | 5.2 fois moins que Anne |
| Andrea | F | 74 | 9151 | 0.8 Andrea sur 100 naissances | 5.3 fois moins que Anne |
| Emeline | F | 108 | 13568 | 0.8 Emeline sur 100 naissances | 5.3 fois moins que Anne |
| Stephanie | F | 106 | 13413 | 0.8 Stephanie sur 100 naissances | 5.4 fois moins que Anne |
| Laurie | F | 109 | 14118 | 0.8 Laurie sur 100 naissances | 5.5 fois moins que Anne |
| Anais | F | 399 | 52121 | 0.8 Anais sur 100 naissances | 5.5 fois moins que Anne |
| Laetitia | F | 156 | 20621 | 0.8 Laetitia sur 100 naissances | 5.6 fois moins que Anne |
| Melanie | F | 334 | 44437 | 0.8 Melanie sur 100 naissances | 5.7 fois moins que Anne |
| Deborah | F | 79 | 10631 | 0.7 Deborah sur 100 naissances | 5.7 fois moins que Anne |
| Fiona | F | 37 | 5062 | 0.7 Fiona sur 100 naissances | 5.8 fois moins que Anne |
| Amandine | F | 230 | 33011 | 0.7 Amandine sur 100 naissances | 6.1 fois moins que Anne |
| Ophelie | F | 132 | 19439 | 0.7 Ophelie sur 100 naissances | 6.3 fois moins que Anne |
| Elodie | F | 308 | 46110 | 0.7 Elodie sur 100 naissances | 6.4 fois moins que Anne |
| Melodie | F | 37 | 5743 | 0.6 Melodie sur 100 naissances | 6.6 fois moins que Anne |
| Adeline | F | 110 | 17260 | 0.6 Adeline sur 100 naissances | 6.7 fois moins que Anne |
| Marina | F | 85 | 13379 | 0.6 Marina sur 100 naissances | 6.7 fois moins que Anne |
| Coralie | F | 132 | 20930 | 0.6 Coralie sur 100 naissances | 6.7 fois moins que Anne |
| Vanessa | F | 44 | 7061 | 0.6 Vanessa sur 100 naissances | 6.8 fois moins que Anne |
| Charlene | F | 96 | 15901 | 0.6 Charlene sur 100 naissances | 7 fois moins que Anne |
| Sandra | F | 73 | 12123 | 0.6 Sandra sur 100 naissances | 7.1 fois moins que Anne |
| Maeva | F | 121 | 20621 | 0.6 Maeva sur 100 naissances | 7.2 fois moins que Anne |
| Ludivine | F | 66 | 12030 | 0.5 Ludivine sur 100 naissances | 7.7 fois moins que Anne |
| Oceane | F | 166 | 31433 | 0.5 Oceane sur 100 naissances | 8 fois moins que Anne |
| Sabrina | F | 70 | 13795 | 0.5 Sabrina sur 100 naissances | 8.4 fois moins que Anne |
| Alicia | F | 66 | 13376 | 0.5 Alicia sur 100 naissances | 8.6 fois moins que Anne |
| Jessica | F | 90 | 19463 | 0.5 Jessica sur 100 naissances | 9.2 fois moins que Anne |
| Tiffany | F | 40 | 8849 | 0.5 Tiffany sur 100 naissances | 9.4 fois moins que Anne |
| Melissa | F | 127 | 28718 | 0.4 Melissa sur 100 naissances | 9.6 fois moins que Anne |
| Cynthia | F | 37 | 8396 | 0.4 Cynthia sur 100 naissances | 9.6 fois moins que Anne |
| Megane | F | 45 | 11392 | 0.4 Megane sur 100 naissances | 10.8 fois moins que Anne |
| Samantha | F | 24 | 7365 | 0.3 Samantha sur 100 naissances | 13 fois moins que Anne |
| Cassandra | F | 27 | 8667 | 0.3 Cassandra sur 100 naissances | 13.6 fois moins que Anne |
| Jennifer | F | 50 | 16734 | 0.3 Jennifer sur 100 naissances | 14.2 fois moins que Anne |
| Kelly | F | 30 | 10102 | 0.3 Kelly sur 100 naissances | 14.3 fois moins que Anne |
| Angelique | F | 41 | 14122 | 0.3 Angelique sur 100 naissances | 14.6 fois moins que Anne |
| Gwendoline | F | 27 | 9363 | 0.3 Gwendoline sur 100 naissances | 14.7 fois moins que Anne |
| Cindy | F | 60 | 21537 | 0.3 Cindy sur 100 naissances | 15.3 fois moins que Anne |
| Alison | F | 26 | 9735 | 0.3 Alison sur 100 naissances | 15.9 fois moins que Anne |
Et maintenant les hommes. Edouard est au top : 2,7% des bébés Edouard sont devenus médecin. Vous voyez tout de suite que c’est moins que Anne ! Et tout en bas du tableau, Dylan. Mais regardez Kevin. Très faible taux, mais en tant que patient·e vous avez plus de chance de rencontrer un Docteur Kevin qu’un Docteur Edouard, tant il y a eu de bébés Kevin.
| prenom | sexe | ecn | naissances | combien | comparaison |
|---|---|---|---|---|---|
| Edouard | M | 155 | 5803 | 2.7 Edouard sur 100 naissances | référence |
| Charles | M | 316 | 13246 | 2.4 Charles sur 100 naissances | 1.1 fois moins que Edouard |
| Gregoire | M | 156 | 6890 | 2.3 Gregoire sur 100 naissances | 1.2 fois moins que Edouard |
| Jean | M | 284 | 13319 | 2.1 Jean sur 100 naissances | 1.3 fois moins que Edouard |
| Paul | M | 609 | 29192 | 2.1 Paul sur 100 naissances | 1.3 fois moins que Edouard |
| Martin | M | 240 | 11641 | 2.1 Martin sur 100 naissances | 1.3 fois moins que Edouard |
| Francois | M | 299 | 16086 | 1.9 Francois sur 100 naissances | 1.4 fois moins que Edouard |
| Jules | M | 158 | 8613 | 1.8 Jules sur 100 naissances | 1.5 fois moins que Edouard |
| Victor | M | 369 | 20466 | 1.8 Victor sur 100 naissances | 1.5 fois moins que Edouard |
| Olivier | M | 204 | 11582 | 1.8 Olivier sur 100 naissances | 1.5 fois moins que Edouard |
| Philippe | M | 103 | 5934 | 1.7 Philippe sur 100 naissances | 1.5 fois moins que Edouard |
| Louis | M | 405 | 23338 | 1.7 Louis sur 100 naissances | 1.5 fois moins que Edouard |
| Arthur | M | 381 | 22037 | 1.7 Arthur sur 100 naissances | 1.5 fois moins que Edouard |
| Pierre | M | 832 | 48924 | 1.7 Pierre sur 100 naissances | 1.6 fois moins que Edouard |
| Gauthier | M | 84 | 5038 | 1.7 Gauthier sur 100 naissances | 1.6 fois moins que Edouard |
| Etienne | M | 165 | 10283 | 1.6 Etienne sur 100 naissances | 1.7 fois moins que Edouard |
| Simon | M | 343 | 21585 | 1.6 Simon sur 100 naissances | 1.7 fois moins que Edouard |
| Jean-Baptiste | M | 169 | 10833 | 1.6 Jean-Baptiste sur 100 naissances | 1.7 fois moins que Edouard |
| Gabriel | M | 152 | 9785 | 1.6 Gabriel sur 100 naissances | 1.7 fois moins que Edouard |
| Antoine | M | 868 | 57607 | 1.5 Antoine sur 100 naissances | 1.8 fois moins que Edouard |
| Xavier | M | 140 | 9693 | 1.4 Xavier sur 100 naissances | 1.8 fois moins que Edouard |
| Marc | M | 137 | 9560 | 1.4 Marc sur 100 naissances | 1.9 fois moins que Edouard |
| Matthieu | M | 318 | 22206 | 1.4 Matthieu sur 100 naissances | 1.9 fois moins que Edouard |
| Raphael | M | 260 | 18373 | 1.4 Raphael sur 100 naissances | 1.9 fois moins que Edouard |
| Hugo | M | 442 | 32168 | 1.4 Hugo sur 100 naissances | 1.9 fois moins que Edouard |
| Thibaut | M | 177 | 12976 | 1.4 Thibaut sur 100 naissances | 2 fois moins que Edouard |
| Thibaud | M | 77 | 5650 | 1.4 Thibaud sur 100 naissances | 2 fois moins que Edouard |
| Luc | M | 72 | 5368 | 1.3 Luc sur 100 naissances | 2 fois moins que Edouard |
| Emmanuel | M | 108 | 8070 | 1.3 Emmanuel sur 100 naissances | 2 fois moins que Edouard |
| Camille | M | 67 | 5329 | 1.3 Camille sur 100 naissances | 2.1 fois moins que Edouard |
| Guillaume | M | 701 | 56507 | 1.2 Guillaume sur 100 naissances | 2.2 fois moins que Edouard |
| Arnaud | M | 243 | 20217 | 1.2 Arnaud sur 100 naissances | 2.2 fois moins que Edouard |
| Thibault | M | 240 | 20152 | 1.2 Thibault sur 100 naissances | 2.2 fois moins que Edouard |
| Clement | M | 617 | 52610 | 1.2 Clement sur 100 naissances | 2.3 fois moins que Edouard |
| Mohamed | M | 144 | 12429 | 1.2 Mohamed sur 100 naissances | 2.3 fois moins que Edouard |
| Laurent | M | 92 | 7956 | 1.2 Laurent sur 100 naissances | 2.3 fois moins que Edouard |
| Robin | M | 174 | 15054 | 1.2 Robin sur 100 naissances | 2.3 fois moins que Edouard |
| Benoit | M | 201 | 17660 | 1.1 Benoit sur 100 naissances | 2.3 fois moins que Edouard |
| Baptiste | M | 296 | 26106 | 1.1 Baptiste sur 100 naissances | 2.4 fois moins que Edouard |
| Antonin | M | 61 | 5711 | 1.1 Antonin sur 100 naissances | 2.5 fois moins que Edouard |
| Thomas | M | 983 | 93158 | 1.1 Thomas sur 100 naissances | 2.5 fois moins que Edouard |
| Adrien | M | 404 | 38525 | 1 Adrien sur 100 naissances | 2.5 fois moins que Edouard |
| Mehdi | M | 133 | 13086 | 1 Mehdi sur 100 naissances | 2.6 fois moins que Edouard |
| Vincent | M | 431 | 42510 | 1 Vincent sur 100 naissances | 2.6 fois moins que Edouard |
| Leo | M | 165 | 16339 | 1 Leo sur 100 naissances | 2.6 fois moins que Edouard |
| Tristan | M | 122 | 12337 | 1 Tristan sur 100 naissances | 2.7 fois moins que Edouard |
| Yanis | M | 62 | 6332 | 1 Yanis sur 100 naissances | 2.7 fois moins que Edouard |
| Alexandre | M | 816 | 84350 | 1 Alexandre sur 100 naissances | 2.8 fois moins que Edouard |
| Eric | M | 49 | 5071 | 1 Eric sur 100 naissances | 2.8 fois moins que Edouard |
| Tom | M | 108 | 11271 | 1 Tom sur 100 naissances | 2.8 fois moins que Edouard |
| Nicolas | M | 790 | 83428 | 0.9 Nicolas sur 100 naissances | 2.8 fois moins que Edouard |
| Frederic | M | 86 | 9203 | 0.9 Frederic sur 100 naissances | 2.9 fois moins que Edouard |
| Samuel | M | 127 | 13707 | 0.9 Samuel sur 100 naissances | 2.9 fois moins que Edouard |
| Theo | M | 253 | 27664 | 0.9 Theo sur 100 naissances | 2.9 fois moins que Edouard |
| Maxence | M | 108 | 12001 | 0.9 Maxence sur 100 naissances | 3 fois moins que Edouard |
| David | M | 239 | 26633 | 0.9 David sur 100 naissances | 3 fois moins que Edouard |
| Nathan | M | 137 | 15377 | 0.9 Nathan sur 100 naissances | 3 fois moins que Edouard |
| Maxime | M | 692 | 78013 | 0.9 Maxime sur 100 naissances | 3 fois moins que Edouard |
| Benjamin | M | 450 | 50742 | 0.9 Benjamin sur 100 naissances | 3 fois moins que Edouard |
| Tanguy | M | 65 | 7396 | 0.9 Tanguy sur 100 naissances | 3 fois moins que Edouard |
| Michael | M | 77 | 8771 | 0.9 Michael sur 100 naissances | 3 fois moins que Edouard |
| Christophe | M | 102 | 11623 | 0.9 Christophe sur 100 naissances | 3 fois moins que Edouard |
| Remi | M | 191 | 22032 | 0.9 Remi sur 100 naissances | 3.1 fois moins que Edouard |
| Julien | M | 601 | 69494 | 0.9 Julien sur 100 naissances | 3.1 fois moins que Edouard |
| Romain | M | 503 | 60159 | 0.8 Romain sur 100 naissances | 3.2 fois moins que Edouard |
| William | M | 108 | 12931 | 0.8 William sur 100 naissances | 3.2 fois moins que Edouard |
| Jeremie | M | 60 | 7251 | 0.8 Jeremie sur 100 naissances | 3.2 fois moins que Edouard |
| Quentin | M | 519 | 62803 | 0.8 Quentin sur 100 naissances | 3.2 fois moins que Edouard |
| Florent | M | 145 | 17724 | 0.8 Florent sur 100 naissances | 3.3 fois moins que Edouard |
| Lucas | M | 302 | 38553 | 0.8 Lucas sur 100 naissances | 3.4 fois moins que Edouard |
| Aymeric | M | 54 | 7009 | 0.8 Aymeric sur 100 naissances | 3.5 fois moins que Edouard |
| Yann | M | 103 | 13541 | 0.8 Yann sur 100 naissances | 3.5 fois moins que Edouard |
| Bastien | M | 151 | 19893 | 0.8 Bastien sur 100 naissances | 3.5 fois moins que Edouard |
| Mathieu | M | 291 | 38922 | 0.7 Mathieu sur 100 naissances | 3.6 fois moins que Edouard |
| Valentin | M | 346 | 46721 | 0.7 Valentin sur 100 naissances | 3.6 fois moins que Edouard |
| Sylvain | M | 98 | 13238 | 0.7 Sylvain sur 100 naissances | 3.6 fois moins que Edouard |
| Aurelien | M | 163 | 22212 | 0.7 Aurelien sur 100 naissances | 3.6 fois moins que Edouard |
| Gael | M | 42 | 5763 | 0.7 Gael sur 100 naissances | 3.7 fois moins que Edouard |
| Stephane | M | 79 | 10988 | 0.7 Stephane sur 100 naissances | 3.7 fois moins que Edouard |
| Sofiane | M | 52 | 7297 | 0.7 Sofiane sur 100 naissances | 3.7 fois moins que Edouard |
| Corentin | M | 173 | 25106 | 0.7 Corentin sur 100 naissances | 3.9 fois moins que Edouard |
| Axel | M | 139 | 20578 | 0.7 Axel sur 100 naissances | 4 fois moins que Edouard |
| Brice | M | 48 | 7300 | 0.7 Brice sur 100 naissances | 4.1 fois moins que Edouard |
| Alexis | M | 322 | 49218 | 0.7 Alexis sur 100 naissances | 4.1 fois moins que Edouard |
| Jerome | M | 92 | 14191 | 0.6 Jerome sur 100 naissances | 4.1 fois moins que Edouard |
| Yoann | M | 75 | 11643 | 0.6 Yoann sur 100 naissances | 4.1 fois moins que Edouard |
| Yannick | M | 33 | 5169 | 0.6 Yannick sur 100 naissances | 4.2 fois moins que Edouard |
| Mathias | M | 49 | 7688 | 0.6 Mathias sur 100 naissances | 4.2 fois moins que Edouard |
| Remy | M | 80 | 12726 | 0.6 Remy sur 100 naissances | 4.2 fois moins que Edouard |
| Cedric | M | 115 | 18651 | 0.6 Cedric sur 100 naissances | 4.3 fois moins que Edouard |
| Sebastien | M | 181 | 29430 | 0.6 Sebastien sur 100 naissances | 4.3 fois moins que Edouard |
| Karim | M | 34 | 5562 | 0.6 Karim sur 100 naissances | 4.4 fois moins que Edouard |
| Fabien | M | 107 | 17889 | 0.6 Fabien sur 100 naissances | 4.5 fois moins que Edouard |
| Loic | M | 156 | 26085 | 0.6 Loic sur 100 naissances | 4.5 fois moins que Edouard |
| Erwan | M | 48 | 8091 | 0.6 Erwan sur 100 naissances | 4.5 fois moins que Edouard |
| Geoffrey | M | 71 | 11988 | 0.6 Geoffrey sur 100 naissances | 4.5 fois moins que Edouard |
| Cyril | M | 81 | 13706 | 0.6 Cyril sur 100 naissances | 4.5 fois moins que Edouard |
| Joris | M | 36 | 6281 | 0.6 Joris sur 100 naissances | 4.7 fois moins que Edouard |
| Charly | M | 30 | 5365 | 0.6 Charly sur 100 naissances | 4.8 fois moins que Edouard |
| Franck | M | 46 | 8279 | 0.6 Franck sur 100 naissances | 4.8 fois moins que Edouard |
| Florian | M | 323 | 59534 | 0.5 Florian sur 100 naissances | 4.9 fois moins que Edouard |
| Johan | M | 39 | 7387 | 0.5 Johan sur 100 naissances | 5.1 fois moins que Edouard |
| Morgan | M | 52 | 10403 | 0.5 Morgan sur 100 naissances | 5.3 fois moins que Edouard |
| Yohan | M | 38 | 7611 | 0.5 Yohan sur 100 naissances | 5.3 fois moins que Edouard |
| Dorian | M | 52 | 10598 | 0.5 Dorian sur 100 naissances | 5.4 fois moins que Edouard |
| Damien | M | 142 | 29411 | 0.5 Damien sur 100 naissances | 5.5 fois moins que Edouard |
| Ludovic | M | 70 | 15363 | 0.5 Ludovic sur 100 naissances | 5.9 fois moins que Edouard |
| Gaetan | M | 70 | 15828 | 0.4 Gaetan sur 100 naissances | 6 fois moins que Edouard |
| Gregory | M | 42 | 9714 | 0.4 Gregory sur 100 naissances | 6.2 fois moins que Edouard |
| Jeremy | M | 213 | 49773 | 0.4 Jeremy sur 100 naissances | 6.2 fois moins que Edouard |
| Jonathan | M | 133 | 31957 | 0.4 Jonathan sur 100 naissances | 6.4 fois moins que Edouard |
| Alex | M | 29 | 7041 | 0.4 Alex sur 100 naissances | 6.5 fois moins que Edouard |
| Mickael | M | 100 | 25295 | 0.4 Mickael sur 100 naissances | 6.8 fois moins que Edouard |
| Enzo | M | 29 | 8249 | 0.4 Enzo sur 100 naissances | 7.6 fois moins que Edouard |
| Alan | M | 21 | 6214 | 0.3 Alan sur 100 naissances | 7.9 fois moins que Edouard |
| Allan | M | 23 | 7062 | 0.3 Allan sur 100 naissances | 8.2 fois moins que Edouard |
| Dimitri | M | 38 | 12920 | 0.3 Dimitri sur 100 naissances | 9.1 fois moins que Edouard |
| Anthony | M | 167 | 60270 | 0.3 Anthony sur 100 naissances | 9.6 fois moins que Edouard |
| Jordan | M | 82 | 34258 | 0.2 Jordan sur 100 naissances | 11.2 fois moins que Edouard |
| Kevin | M | 218 | 92100 | 0.2 Kevin sur 100 naissances | 11.3 fois moins que Edouard |
| Steven | M | 34 | 15303 | 0.2 Steven sur 100 naissances | 12 fois moins que Edouard |
| Bryan | M | 22 | 10521 | 0.2 Bryan sur 100 naissances | 12.8 fois moins que Edouard |
| Jimmy | M | 20 | 9883 | 0.2 Jimmy sur 100 naissances | 13.2 fois moins que Edouard |
| Tony | M | 16 | 9773 | 0.2 Tony sur 100 naissances | 16.3 fois moins que Edouard |
| Christopher | M | 28 | 17917 | 0.2 Christopher sur 100 naissances | 17.1 fois moins que Edouard |
| Jason | M | 15 | 10055 | 0.1 Jason sur 100 naissances | 17.9 fois moins que Edouard |
| Dylan | M | 41 | 33768 | 0.1 Dylan sur 100 naissances | 22 fois moins que Edouard |
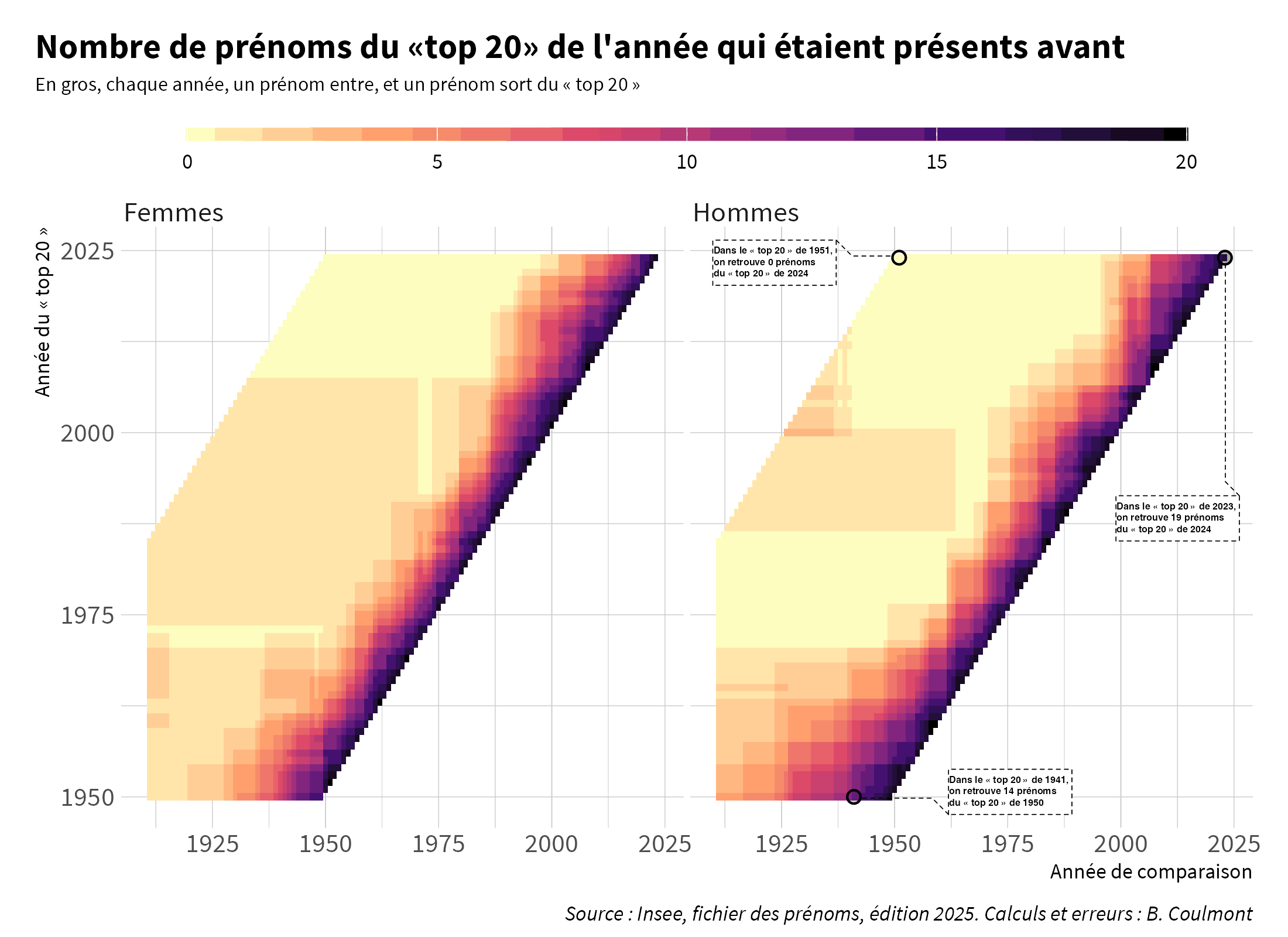
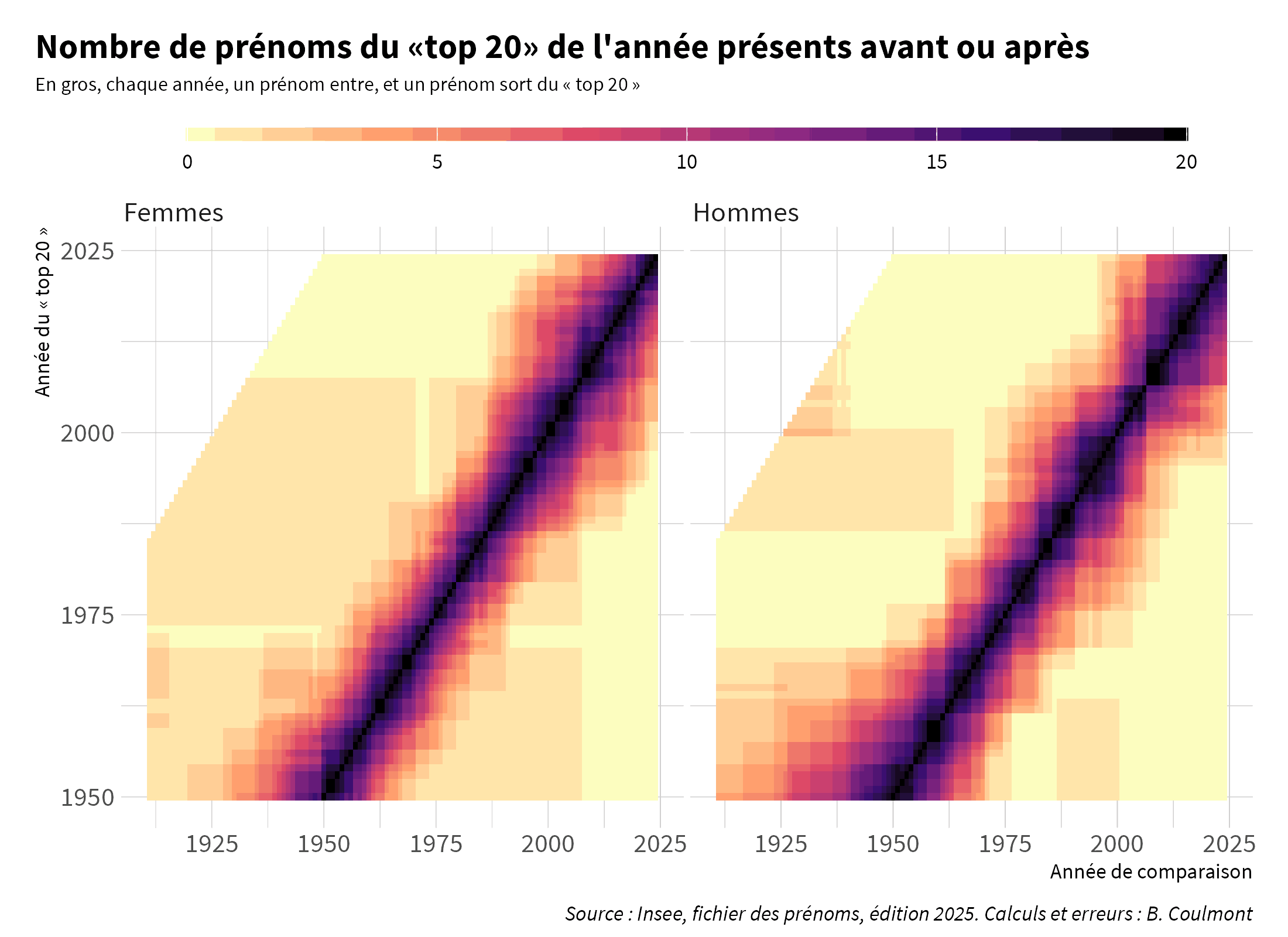
 Parce qu’on peut disposer assez facilement de listes de prénoms, ces listes ont souvent été utilisées pour étudier les réactions des populations à des événements comme des guerres ou des crises diplomatiques. Mais on prend en général quelques prénoms « candidats » et on étudie la variation de leur fréquence parmi les naissances qui ont lieu à proximité de l’événement étudié : le prénom « Philippe » quand Pétain arrive au pouvoir ? le prénom « Adolphe » après 1940 ? le prénom « John » au moment de la Crise de Cuba, etc…
Parce qu’on peut disposer assez facilement de listes de prénoms, ces listes ont souvent été utilisées pour étudier les réactions des populations à des événements comme des guerres ou des crises diplomatiques. Mais on prend en général quelques prénoms « candidats » et on étudie la variation de leur fréquence parmi les naissances qui ont lieu à proximité de l’événement étudié : le prénom « Philippe » quand Pétain arrive au pouvoir ? le prénom « Adolphe » après 1940 ? le prénom « John » au moment de la Crise de Cuba, etc…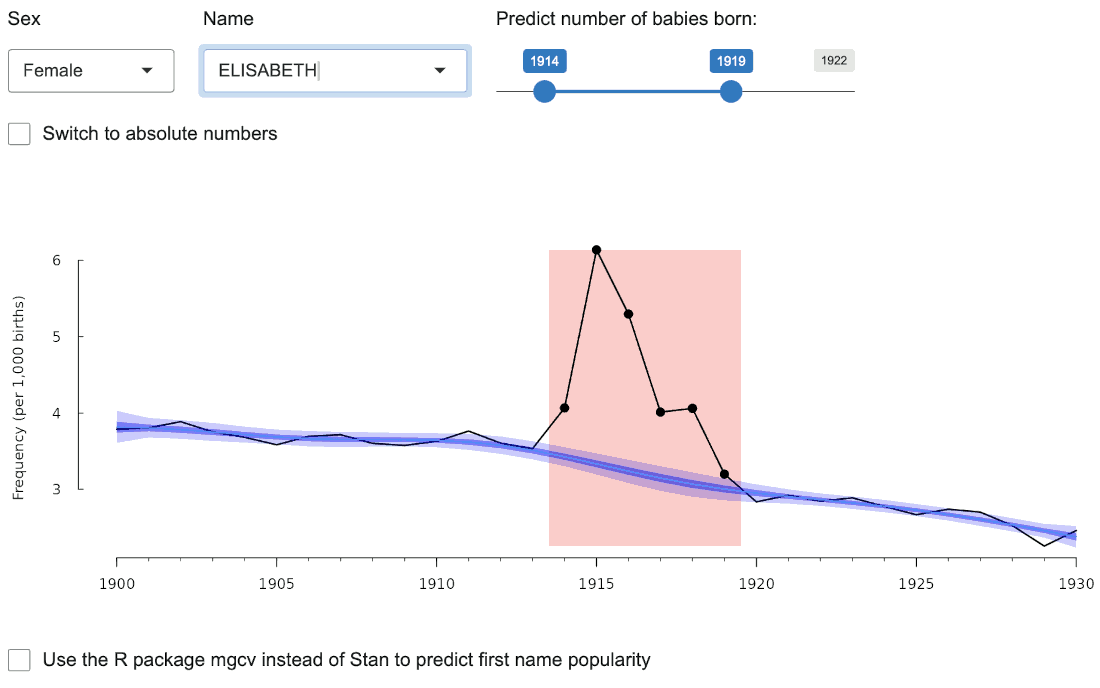




 Le treize octobre mil neuf cent quinze, onze heures du matin, Louis Jardin, quarante quatre ans, Commissaire spécial de Police à la Gare de l’Est, demeurant 81 rue Madame, nous a déclaré qu’hier à huit heures cinquante cinq minutes du matin, un enfant du sexe féminin paraissant âgé de six semaines environ a été abandonné à la Gare de l’Est dans la salle des Pas Perdus et qu’il a été dressé par lui de cet abandon le procès verbal dont la teneur suit :
Le treize octobre mil neuf cent quinze, onze heures du matin, Louis Jardin, quarante quatre ans, Commissaire spécial de Police à la Gare de l’Est, demeurant 81 rue Madame, nous a déclaré qu’hier à huit heures cinquante cinq minutes du matin, un enfant du sexe féminin paraissant âgé de six semaines environ a été abandonné à la Gare de l’Est dans la salle des Pas Perdus et qu’il a été dressé par lui de cet abandon le procès verbal dont la teneur suit :
 , âgée de vingt sept ans, sténographe, demeurant 144 route de Saint-Leu à Montmorency, Seine et Oise, qui, pressée de prendre le train, nous a fait verbalement la déclaration suivante et en présence du Gardien de la Paix Vallée Georges 28 ans, du dixième arrondissement:
, âgée de vingt sept ans, sténographe, demeurant 144 route de Saint-Leu à Montmorency, Seine et Oise, qui, pressée de prendre le train, nous a fait verbalement la déclaration suivante et en présence du Gardien de la Paix Vallée Georges 28 ans, du dixième arrondissement: Elle répondit négativement en ajoutant que son lait était aigre et en me priant de lui garder son enfant le temps strictement nécessaire pour aller chercher du lait. Ayant acquiescé à sa demande, elle m’a remis son enfant, lui laissant sa tétine dans la bouche, puis emportant la bouteille elle disparut. Il était à ce moment là 8h55. Or à 9h45 étant obligée de partir pour prendre mon train et ne voyant pas revenir cette dame, j’ai cru comprendre que cette dernière avait eu recours à ce subterfuge dans le but de se débarrasser de son enfant. J’en ai avisé le gardien de la paix ici présent et lui confiant cet enfant, je l’ai prié de le porter à votre commissariat.
Elle répondit négativement en ajoutant que son lait était aigre et en me priant de lui garder son enfant le temps strictement nécessaire pour aller chercher du lait. Ayant acquiescé à sa demande, elle m’a remis son enfant, lui laissant sa tétine dans la bouche, puis emportant la bouteille elle disparut. Il était à ce moment là 8h55. Or à 9h45 étant obligée de partir pour prendre mon train et ne voyant pas revenir cette dame, j’ai cru comprendre que cette dernière avait eu recours à ce subterfuge dans le but de se débarrasser de son enfant. J’en ai avisé le gardien de la paix ici présent et lui confiant cet enfant, je l’ai prié de le porter à votre commissariat. 
 infirmière, attachée à la Cantine Militaire de la Gare de l’Est, avec un rapport pour le Directeur de cet Etablissement, signé Jardin.
infirmière, attachée à la Cantine Militaire de la Gare de l’Est, avec un rapport pour le Directeur de cet Etablissement, signé Jardin.