Plusieurs articles récents viennent éclairer l’état actuel de la sociologie française. Un article de Demazière, un autre de Stéphane Beaud. Je voulais apporter ma contribution au débat. Beaud et Demazières diagnostiquent la sociologie française depuis leur position, et les méchantes langues disent que ces articles reflètent moins l’état actuel de la sociologie française que l’état actuel de Beaud et Demazière. Mon approche est différente : de par mes fonctions au CNU, et intéressé par l’objectivation statistique de la discipline, j’ai recueilli le jury de soutenance de tous les candidats à la qualification en section 19 cette année (un peu plus de 500) [ce qui vient compléter l’étude de la proximité entre sections du CNU et permettra de mieux rédiger le rapport annuel de la section].
On sait, par les travaux de Godechot notamment [un exemple ici], que les jurys de soutenance permettent d’établir d’intéressants constats. Beaud, par exemple, à la fois par sa position institutionnelle, ses intérêts scientifiques, sa connaissance du comportement des collègues… n’invite pas n’importe qui aux soutenances de ses doctorantes. Et c’est la même chose pour tous les autres.
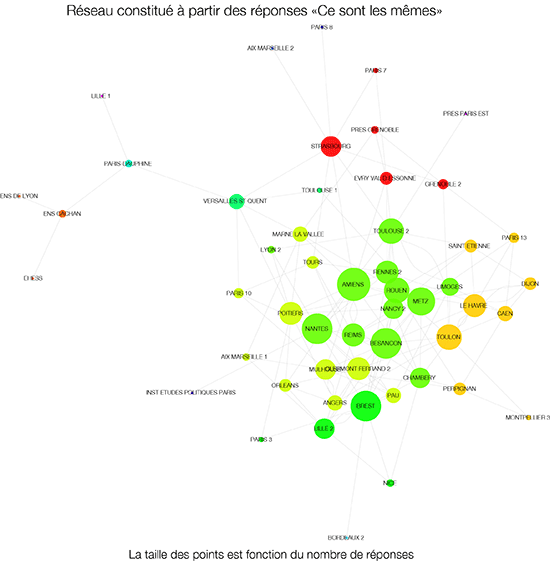
Ces invitations et co-participations permettent de dresser une sorte de carte de la sociologie française, en utilisant un algorithme qui rapproche les personnes qui s’invitent les unes les autres aux jurys de thèse.

Cliquez pour télécharger un fichier PDF zoomable (mais pas toujours très lisible)
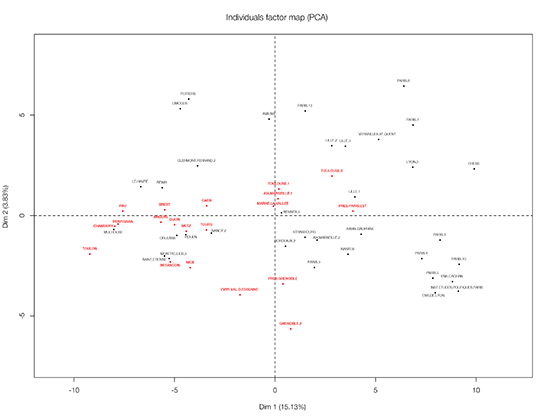
Sur ce graphe présentant une sélection des données [1] vous constaterez qu’au Nord se trouve une certaine sociologie économique (autour de Flichy, Cochoy, Paradeise, Vatin, Grossetti, Segrestin, Licoppe) Weber et Steiner se trouvent un peu plus au sud de ces personnes.
Au Sud-Sud commence l’empire du STAPS, avec During, qui se poursuit au Sud-Est où se trouve plusieurs représentant de la sociologie/anthropologie du corps, ou ce qu’on appelle les “STAPS” : Andrieu, Héas, Le Breton, Bodin, Duret. Dans la même zone se trouve aussi plusieurs représentants de la sociologie du travail (Bercot, Lallemand, Demazière, Gadéa) : une représentation n’utilisant que deux dimension fait se superposer des personnes ayant peu de liens.
A l’Ouest se trouve les islamisants ou les spécialistes des relations interethniques Roy, Fregosi, Khosrokhavar, Gole, Streiff-fenart.
Au coeur de la constellation vont se trouver les politistes (Spire, Deloye, Gaiti, Offerlé, Sommier) et un groupe où je retiens les noms de Beaud, Mauger, Schwartz, Lagrave Marry, Carricaburu, Fabiani, Sapiro…
Au total, les liens multiples engendrés par les jurys de soutenances ne dessinent pas un monde fragmenté, où une faction serait ostracisée par toutes les autres. Au contraire, des liens multiples relient tout le monde avec tout le monde.
Certes la méthode ici utilisée a ses nombreuses limites : il faudrait, sur une période plus longue, mettre en valeur les liens répétés, ou les invitations rendues. Pour l’instant, mes données permettent de repérer certains liens habituels (qui sont épais, sur le graphe), mais ces liens sont peu nombreux (et tendraient à faire ressortir les politistes). Rendez-vous l’année prochaine pour une étude sur deux ans.
Notes : [1] n’ont été retenues que les individus invitées au moins 2 fois ou ayant été directeures d’au moins une thèse.
 La Revue française de sociologie a placé mon article, « Tenir le haut de l’affiche. Analyse structurale des prétentions au charisme » en accès libre. Il est disponible ici en PDF : http://www.rfs-revue.com/sites/rfs/IMG/pdf/RFS-2013-3-B-_Coulmont.pdf.
La Revue française de sociologie a placé mon article, « Tenir le haut de l’affiche. Analyse structurale des prétentions au charisme » en accès libre. Il est disponible ici en PDF : http://www.rfs-revue.com/sites/rfs/IMG/pdf/RFS-2013-3-B-_Coulmont.pdf.



 Explorez le graphe en haute résolution
Explorez le graphe en haute résolution





