| Edouard |
M |
155 |
5803 |
2.7 Edouard sur 100 naissances |
référence |
| Charles |
M |
316 |
13246 |
2.4 Charles sur 100 naissances |
1.1 fois moins que Edouard |
| Gregoire |
M |
156 |
6890 |
2.3 Gregoire sur 100 naissances |
1.2 fois moins que Edouard |
| Jean |
M |
284 |
13319 |
2.1 Jean sur 100 naissances |
1.3 fois moins que Edouard |
| Paul |
M |
609 |
29192 |
2.1 Paul sur 100 naissances |
1.3 fois moins que Edouard |
| Martin |
M |
240 |
11641 |
2.1 Martin sur 100 naissances |
1.3 fois moins que Edouard |
| Francois |
M |
299 |
16086 |
1.9 Francois sur 100 naissances |
1.4 fois moins que Edouard |
| Jules |
M |
158 |
8613 |
1.8 Jules sur 100 naissances |
1.5 fois moins que Edouard |
| Victor |
M |
369 |
20466 |
1.8 Victor sur 100 naissances |
1.5 fois moins que Edouard |
| Olivier |
M |
204 |
11582 |
1.8 Olivier sur 100 naissances |
1.5 fois moins que Edouard |
| Philippe |
M |
103 |
5934 |
1.7 Philippe sur 100 naissances |
1.5 fois moins que Edouard |
| Louis |
M |
405 |
23338 |
1.7 Louis sur 100 naissances |
1.5 fois moins que Edouard |
| Arthur |
M |
381 |
22037 |
1.7 Arthur sur 100 naissances |
1.5 fois moins que Edouard |
| Pierre |
M |
832 |
48924 |
1.7 Pierre sur 100 naissances |
1.6 fois moins que Edouard |
| Gauthier |
M |
84 |
5038 |
1.7 Gauthier sur 100 naissances |
1.6 fois moins que Edouard |
| Etienne |
M |
165 |
10283 |
1.6 Etienne sur 100 naissances |
1.7 fois moins que Edouard |
| Simon |
M |
343 |
21585 |
1.6 Simon sur 100 naissances |
1.7 fois moins que Edouard |
| Jean-Baptiste |
M |
169 |
10833 |
1.6 Jean-Baptiste sur 100 naissances |
1.7 fois moins que Edouard |
| Gabriel |
M |
152 |
9785 |
1.6 Gabriel sur 100 naissances |
1.7 fois moins que Edouard |
| Antoine |
M |
868 |
57607 |
1.5 Antoine sur 100 naissances |
1.8 fois moins que Edouard |
| Xavier |
M |
140 |
9693 |
1.4 Xavier sur 100 naissances |
1.8 fois moins que Edouard |
| Marc |
M |
137 |
9560 |
1.4 Marc sur 100 naissances |
1.9 fois moins que Edouard |
| Matthieu |
M |
318 |
22206 |
1.4 Matthieu sur 100 naissances |
1.9 fois moins que Edouard |
| Raphael |
M |
260 |
18373 |
1.4 Raphael sur 100 naissances |
1.9 fois moins que Edouard |
| Hugo |
M |
442 |
32168 |
1.4 Hugo sur 100 naissances |
1.9 fois moins que Edouard |
| Thibaut |
M |
177 |
12976 |
1.4 Thibaut sur 100 naissances |
2 fois moins que Edouard |
| Thibaud |
M |
77 |
5650 |
1.4 Thibaud sur 100 naissances |
2 fois moins que Edouard |
| Luc |
M |
72 |
5368 |
1.3 Luc sur 100 naissances |
2 fois moins que Edouard |
| Emmanuel |
M |
108 |
8070 |
1.3 Emmanuel sur 100 naissances |
2 fois moins que Edouard |
| Camille |
M |
67 |
5329 |
1.3 Camille sur 100 naissances |
2.1 fois moins que Edouard |
| Guillaume |
M |
701 |
56507 |
1.2 Guillaume sur 100 naissances |
2.2 fois moins que Edouard |
| Arnaud |
M |
243 |
20217 |
1.2 Arnaud sur 100 naissances |
2.2 fois moins que Edouard |
| Thibault |
M |
240 |
20152 |
1.2 Thibault sur 100 naissances |
2.2 fois moins que Edouard |
| Clement |
M |
617 |
52610 |
1.2 Clement sur 100 naissances |
2.3 fois moins que Edouard |
| Mohamed |
M |
144 |
12429 |
1.2 Mohamed sur 100 naissances |
2.3 fois moins que Edouard |
| Laurent |
M |
92 |
7956 |
1.2 Laurent sur 100 naissances |
2.3 fois moins que Edouard |
| Robin |
M |
174 |
15054 |
1.2 Robin sur 100 naissances |
2.3 fois moins que Edouard |
| Benoit |
M |
201 |
17660 |
1.1 Benoit sur 100 naissances |
2.3 fois moins que Edouard |
| Baptiste |
M |
296 |
26106 |
1.1 Baptiste sur 100 naissances |
2.4 fois moins que Edouard |
| Antonin |
M |
61 |
5711 |
1.1 Antonin sur 100 naissances |
2.5 fois moins que Edouard |
| Thomas |
M |
983 |
93158 |
1.1 Thomas sur 100 naissances |
2.5 fois moins que Edouard |
| Adrien |
M |
404 |
38525 |
1 Adrien sur 100 naissances |
2.5 fois moins que Edouard |
| Mehdi |
M |
133 |
13086 |
1 Mehdi sur 100 naissances |
2.6 fois moins que Edouard |
| Vincent |
M |
431 |
42510 |
1 Vincent sur 100 naissances |
2.6 fois moins que Edouard |
| Leo |
M |
165 |
16339 |
1 Leo sur 100 naissances |
2.6 fois moins que Edouard |
| Tristan |
M |
122 |
12337 |
1 Tristan sur 100 naissances |
2.7 fois moins que Edouard |
| Yanis |
M |
62 |
6332 |
1 Yanis sur 100 naissances |
2.7 fois moins que Edouard |
| Alexandre |
M |
816 |
84350 |
1 Alexandre sur 100 naissances |
2.8 fois moins que Edouard |
| Eric |
M |
49 |
5071 |
1 Eric sur 100 naissances |
2.8 fois moins que Edouard |
| Tom |
M |
108 |
11271 |
1 Tom sur 100 naissances |
2.8 fois moins que Edouard |
| Nicolas |
M |
790 |
83428 |
0.9 Nicolas sur 100 naissances |
2.8 fois moins que Edouard |
| Frederic |
M |
86 |
9203 |
0.9 Frederic sur 100 naissances |
2.9 fois moins que Edouard |
| Samuel |
M |
127 |
13707 |
0.9 Samuel sur 100 naissances |
2.9 fois moins que Edouard |
| Theo |
M |
253 |
27664 |
0.9 Theo sur 100 naissances |
2.9 fois moins que Edouard |
| Maxence |
M |
108 |
12001 |
0.9 Maxence sur 100 naissances |
3 fois moins que Edouard |
| David |
M |
239 |
26633 |
0.9 David sur 100 naissances |
3 fois moins que Edouard |
| Nathan |
M |
137 |
15377 |
0.9 Nathan sur 100 naissances |
3 fois moins que Edouard |
| Maxime |
M |
692 |
78013 |
0.9 Maxime sur 100 naissances |
3 fois moins que Edouard |
| Benjamin |
M |
450 |
50742 |
0.9 Benjamin sur 100 naissances |
3 fois moins que Edouard |
| Tanguy |
M |
65 |
7396 |
0.9 Tanguy sur 100 naissances |
3 fois moins que Edouard |
| Michael |
M |
77 |
8771 |
0.9 Michael sur 100 naissances |
3 fois moins que Edouard |
| Christophe |
M |
102 |
11623 |
0.9 Christophe sur 100 naissances |
3 fois moins que Edouard |
| Remi |
M |
191 |
22032 |
0.9 Remi sur 100 naissances |
3.1 fois moins que Edouard |
| Julien |
M |
601 |
69494 |
0.9 Julien sur 100 naissances |
3.1 fois moins que Edouard |
| Romain |
M |
503 |
60159 |
0.8 Romain sur 100 naissances |
3.2 fois moins que Edouard |
| William |
M |
108 |
12931 |
0.8 William sur 100 naissances |
3.2 fois moins que Edouard |
| Jeremie |
M |
60 |
7251 |
0.8 Jeremie sur 100 naissances |
3.2 fois moins que Edouard |
| Quentin |
M |
519 |
62803 |
0.8 Quentin sur 100 naissances |
3.2 fois moins que Edouard |
| Florent |
M |
145 |
17724 |
0.8 Florent sur 100 naissances |
3.3 fois moins que Edouard |
| Lucas |
M |
302 |
38553 |
0.8 Lucas sur 100 naissances |
3.4 fois moins que Edouard |
| Aymeric |
M |
54 |
7009 |
0.8 Aymeric sur 100 naissances |
3.5 fois moins que Edouard |
| Yann |
M |
103 |
13541 |
0.8 Yann sur 100 naissances |
3.5 fois moins que Edouard |
| Bastien |
M |
151 |
19893 |
0.8 Bastien sur 100 naissances |
3.5 fois moins que Edouard |
| Mathieu |
M |
291 |
38922 |
0.7 Mathieu sur 100 naissances |
3.6 fois moins que Edouard |
| Valentin |
M |
346 |
46721 |
0.7 Valentin sur 100 naissances |
3.6 fois moins que Edouard |
| Sylvain |
M |
98 |
13238 |
0.7 Sylvain sur 100 naissances |
3.6 fois moins que Edouard |
| Aurelien |
M |
163 |
22212 |
0.7 Aurelien sur 100 naissances |
3.6 fois moins que Edouard |
| Gael |
M |
42 |
5763 |
0.7 Gael sur 100 naissances |
3.7 fois moins que Edouard |
| Stephane |
M |
79 |
10988 |
0.7 Stephane sur 100 naissances |
3.7 fois moins que Edouard |
| Sofiane |
M |
52 |
7297 |
0.7 Sofiane sur 100 naissances |
3.7 fois moins que Edouard |
| Corentin |
M |
173 |
25106 |
0.7 Corentin sur 100 naissances |
3.9 fois moins que Edouard |
| Axel |
M |
139 |
20578 |
0.7 Axel sur 100 naissances |
4 fois moins que Edouard |
| Brice |
M |
48 |
7300 |
0.7 Brice sur 100 naissances |
4.1 fois moins que Edouard |
| Alexis |
M |
322 |
49218 |
0.7 Alexis sur 100 naissances |
4.1 fois moins que Edouard |
| Jerome |
M |
92 |
14191 |
0.6 Jerome sur 100 naissances |
4.1 fois moins que Edouard |
| Yoann |
M |
75 |
11643 |
0.6 Yoann sur 100 naissances |
4.1 fois moins que Edouard |
| Yannick |
M |
33 |
5169 |
0.6 Yannick sur 100 naissances |
4.2 fois moins que Edouard |
| Mathias |
M |
49 |
7688 |
0.6 Mathias sur 100 naissances |
4.2 fois moins que Edouard |
| Remy |
M |
80 |
12726 |
0.6 Remy sur 100 naissances |
4.2 fois moins que Edouard |
| Cedric |
M |
115 |
18651 |
0.6 Cedric sur 100 naissances |
4.3 fois moins que Edouard |
| Sebastien |
M |
181 |
29430 |
0.6 Sebastien sur 100 naissances |
4.3 fois moins que Edouard |
| Karim |
M |
34 |
5562 |
0.6 Karim sur 100 naissances |
4.4 fois moins que Edouard |
| Fabien |
M |
107 |
17889 |
0.6 Fabien sur 100 naissances |
4.5 fois moins que Edouard |
| Loic |
M |
156 |
26085 |
0.6 Loic sur 100 naissances |
4.5 fois moins que Edouard |
| Erwan |
M |
48 |
8091 |
0.6 Erwan sur 100 naissances |
4.5 fois moins que Edouard |
| Geoffrey |
M |
71 |
11988 |
0.6 Geoffrey sur 100 naissances |
4.5 fois moins que Edouard |
| Cyril |
M |
81 |
13706 |
0.6 Cyril sur 100 naissances |
4.5 fois moins que Edouard |
| Joris |
M |
36 |
6281 |
0.6 Joris sur 100 naissances |
4.7 fois moins que Edouard |
| Charly |
M |
30 |
5365 |
0.6 Charly sur 100 naissances |
4.8 fois moins que Edouard |
| Franck |
M |
46 |
8279 |
0.6 Franck sur 100 naissances |
4.8 fois moins que Edouard |
| Florian |
M |
323 |
59534 |
0.5 Florian sur 100 naissances |
4.9 fois moins que Edouard |
| Johan |
M |
39 |
7387 |
0.5 Johan sur 100 naissances |
5.1 fois moins que Edouard |
| Morgan |
M |
52 |
10403 |
0.5 Morgan sur 100 naissances |
5.3 fois moins que Edouard |
| Yohan |
M |
38 |
7611 |
0.5 Yohan sur 100 naissances |
5.3 fois moins que Edouard |
| Dorian |
M |
52 |
10598 |
0.5 Dorian sur 100 naissances |
5.4 fois moins que Edouard |
| Damien |
M |
142 |
29411 |
0.5 Damien sur 100 naissances |
5.5 fois moins que Edouard |
| Ludovic |
M |
70 |
15363 |
0.5 Ludovic sur 100 naissances |
5.9 fois moins que Edouard |
| Gaetan |
M |
70 |
15828 |
0.4 Gaetan sur 100 naissances |
6 fois moins que Edouard |
| Gregory |
M |
42 |
9714 |
0.4 Gregory sur 100 naissances |
6.2 fois moins que Edouard |
| Jeremy |
M |
213 |
49773 |
0.4 Jeremy sur 100 naissances |
6.2 fois moins que Edouard |
| Jonathan |
M |
133 |
31957 |
0.4 Jonathan sur 100 naissances |
6.4 fois moins que Edouard |
| Alex |
M |
29 |
7041 |
0.4 Alex sur 100 naissances |
6.5 fois moins que Edouard |
| Mickael |
M |
100 |
25295 |
0.4 Mickael sur 100 naissances |
6.8 fois moins que Edouard |
| Enzo |
M |
29 |
8249 |
0.4 Enzo sur 100 naissances |
7.6 fois moins que Edouard |
| Alan |
M |
21 |
6214 |
0.3 Alan sur 100 naissances |
7.9 fois moins que Edouard |
| Allan |
M |
23 |
7062 |
0.3 Allan sur 100 naissances |
8.2 fois moins que Edouard |
| Dimitri |
M |
38 |
12920 |
0.3 Dimitri sur 100 naissances |
9.1 fois moins que Edouard |
| Anthony |
M |
167 |
60270 |
0.3 Anthony sur 100 naissances |
9.6 fois moins que Edouard |
| Jordan |
M |
82 |
34258 |
0.2 Jordan sur 100 naissances |
11.2 fois moins que Edouard |
| Kevin |
M |
218 |
92100 |
0.2 Kevin sur 100 naissances |
11.3 fois moins que Edouard |
| Steven |
M |
34 |
15303 |
0.2 Steven sur 100 naissances |
12 fois moins que Edouard |
| Bryan |
M |
22 |
10521 |
0.2 Bryan sur 100 naissances |
12.8 fois moins que Edouard |
| Jimmy |
M |
20 |
9883 |
0.2 Jimmy sur 100 naissances |
13.2 fois moins que Edouard |
| Tony |
M |
16 |
9773 |
0.2 Tony sur 100 naissances |
16.3 fois moins que Edouard |
| Christopher |
M |
28 |
17917 |
0.2 Christopher sur 100 naissances |
17.1 fois moins que Edouard |
| Jason |
M |
15 |
10055 |
0.1 Jason sur 100 naissances |
17.9 fois moins que Edouard |
| Dylan |
M |
41 |
33768 |
0.1 Dylan sur 100 naissances |
22 fois moins que Edouard |
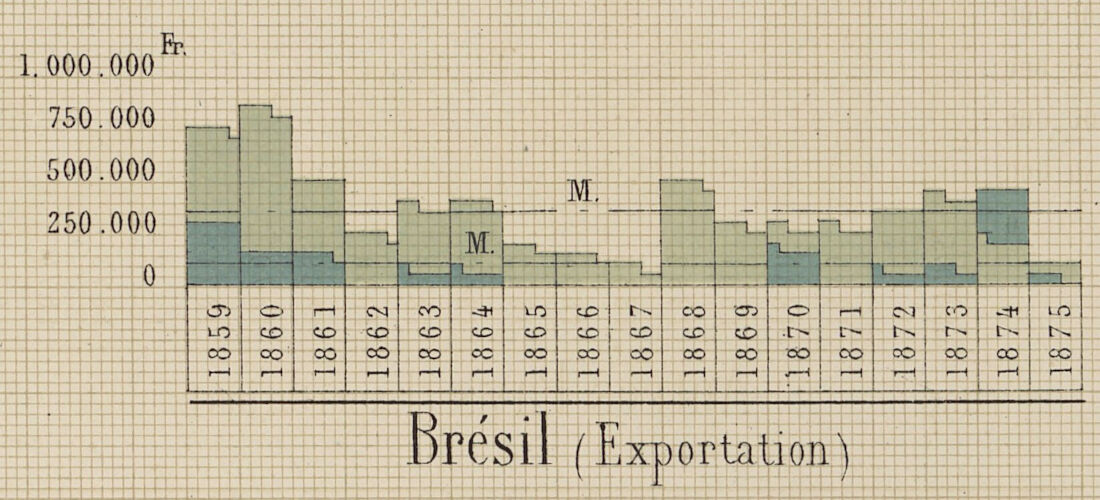
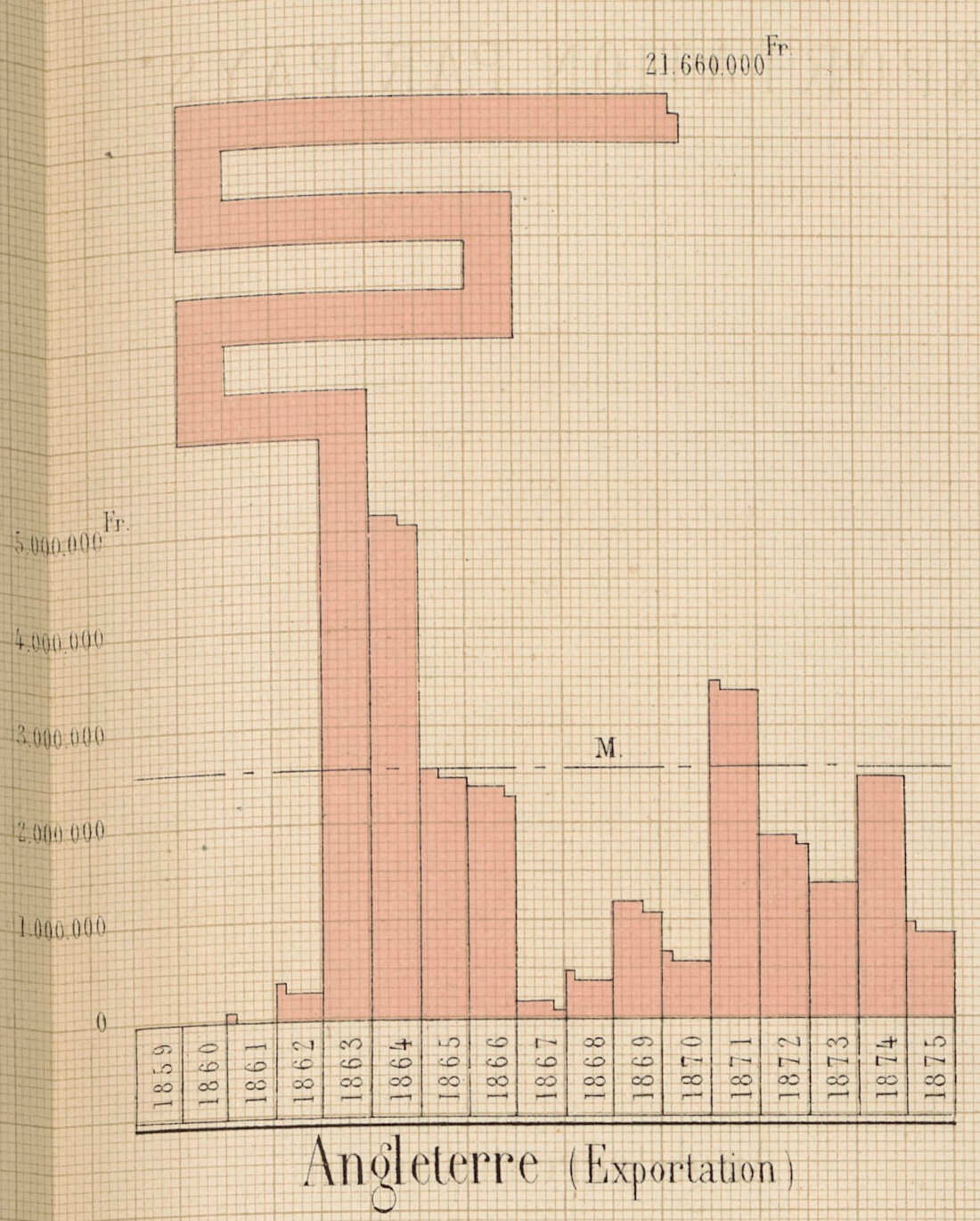
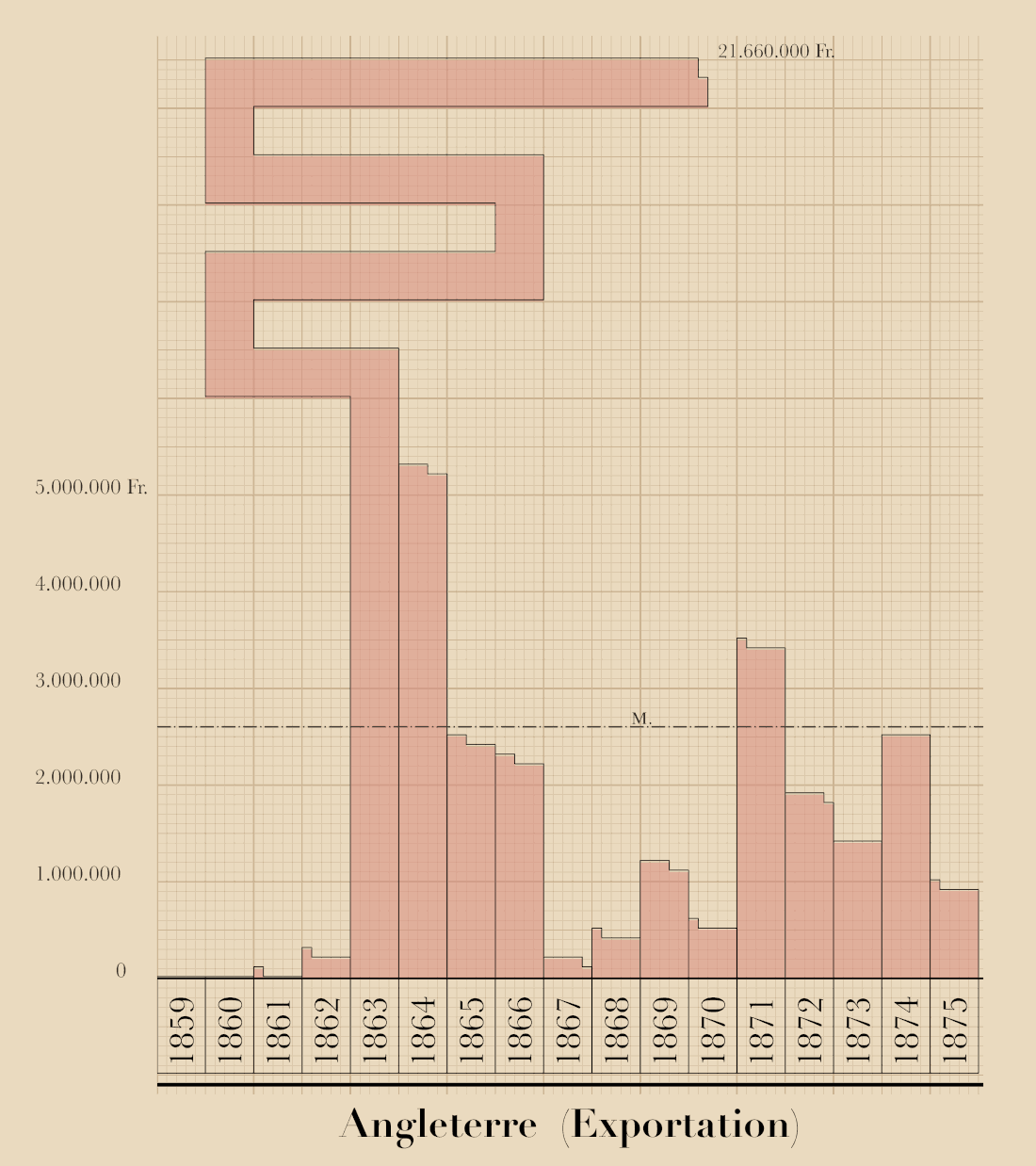 En 1878, Ferdinand Bonnange, alors sous-chef de bureau au ministère de l’agriculture et du commerce, publie un Atlas graphique et statistique du commerce de la France avec les pays étrangers, pour les principales marchandises, pendant les années 1859 à 1875. Cet ouvrage est primé lors de l’exposition universelle qui se tient la même année.
En 1878, Ferdinand Bonnange, alors sous-chef de bureau au ministère de l’agriculture et du commerce, publie un Atlas graphique et statistique du commerce de la France avec les pays étrangers, pour les principales marchandises, pendant les années 1859 à 1875. Cet ouvrage est primé lors de l’exposition universelle qui se tient la même année.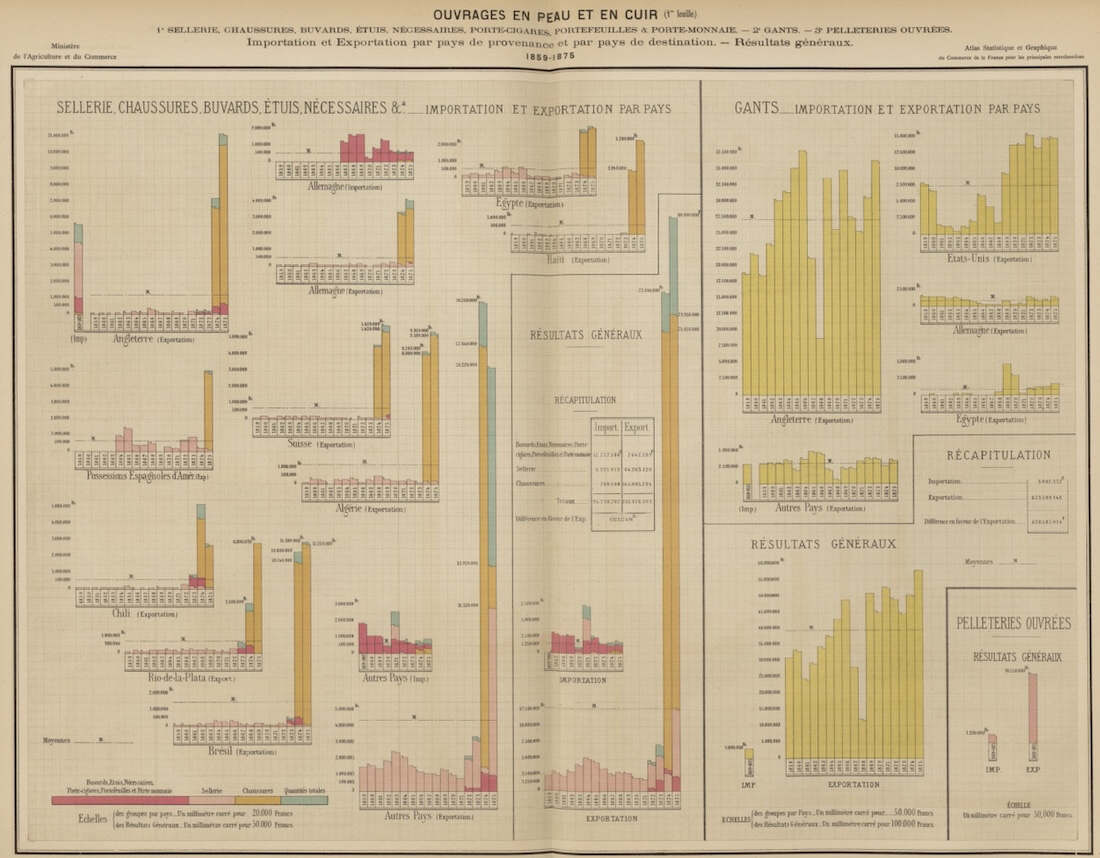
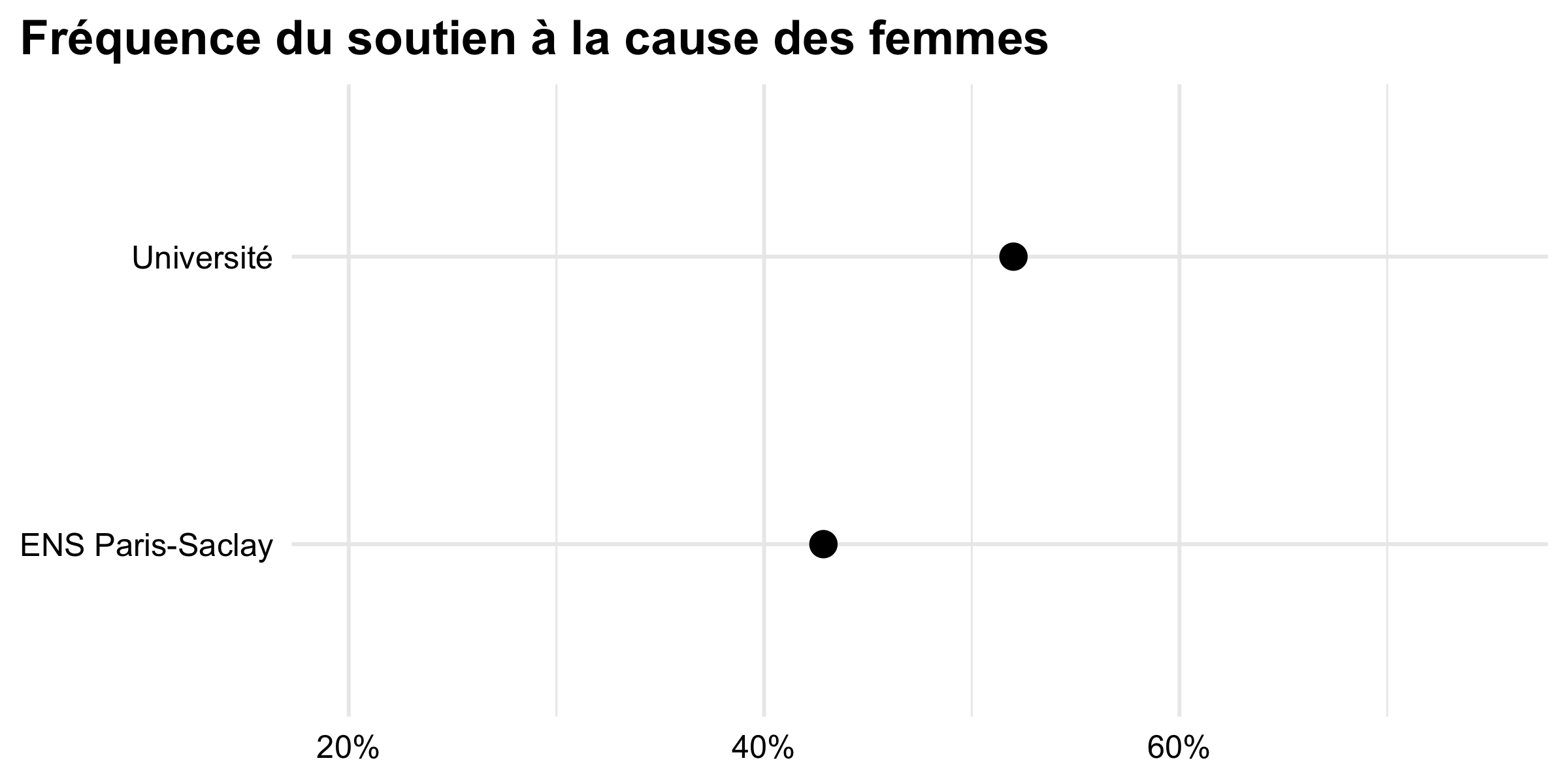
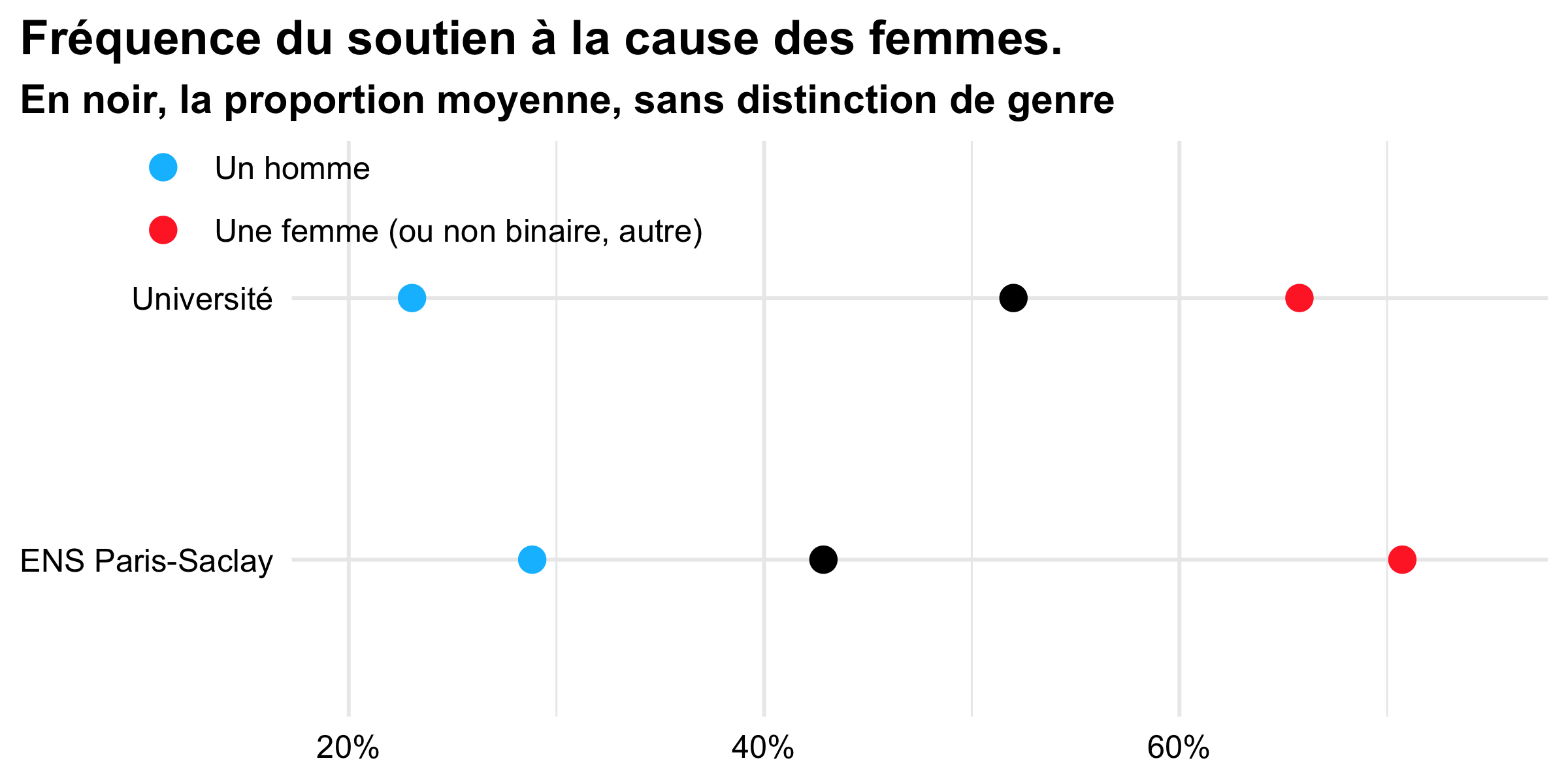
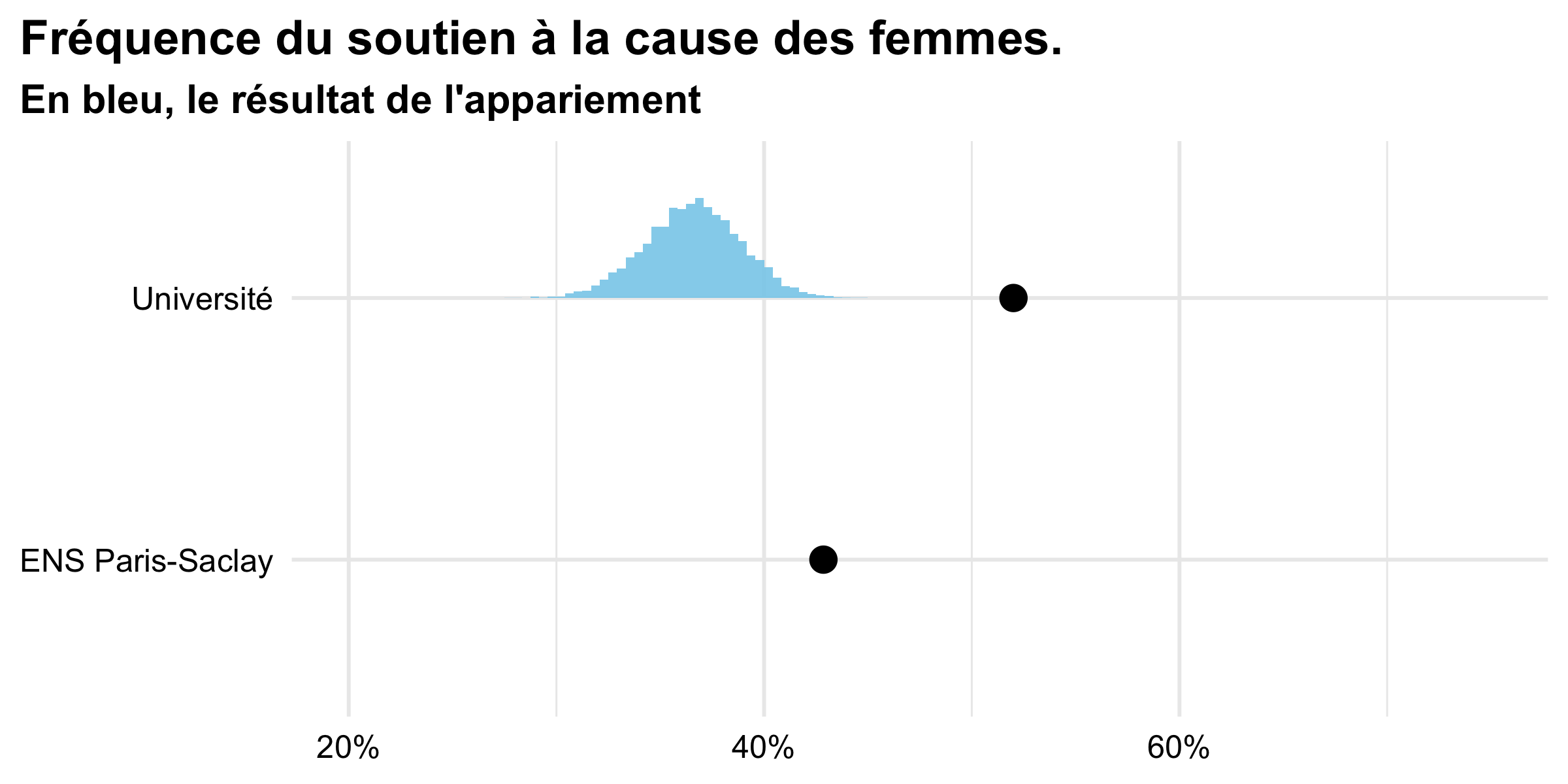
 Avec un financement de l’université Paris-Saclay, nous avons aussi pu organiser une journée d’étude « étudiante », à l’ENS Paris-Saclay à la fin du mois d’avril. En présence des enseignant·e·s du dispositif, des étudiant·e·s de L2 et L3 de l’UVSQ, de l’ENS et de l’université Paris 8 ont pu présenter les premiers résultats de l’enquête, avec des étudiants de master de l’université Paris 1, qui avaient participé à une enquête sur des thèmes proches, l’année dernière.
Avec un financement de l’université Paris-Saclay, nous avons aussi pu organiser une journée d’étude « étudiante », à l’ENS Paris-Saclay à la fin du mois d’avril. En présence des enseignant·e·s du dispositif, des étudiant·e·s de L2 et L3 de l’UVSQ, de l’ENS et de l’université Paris 8 ont pu présenter les premiers résultats de l’enquête, avec des étudiants de master de l’université Paris 1, qui avaient participé à une enquête sur des thèmes proches, l’année dernière.

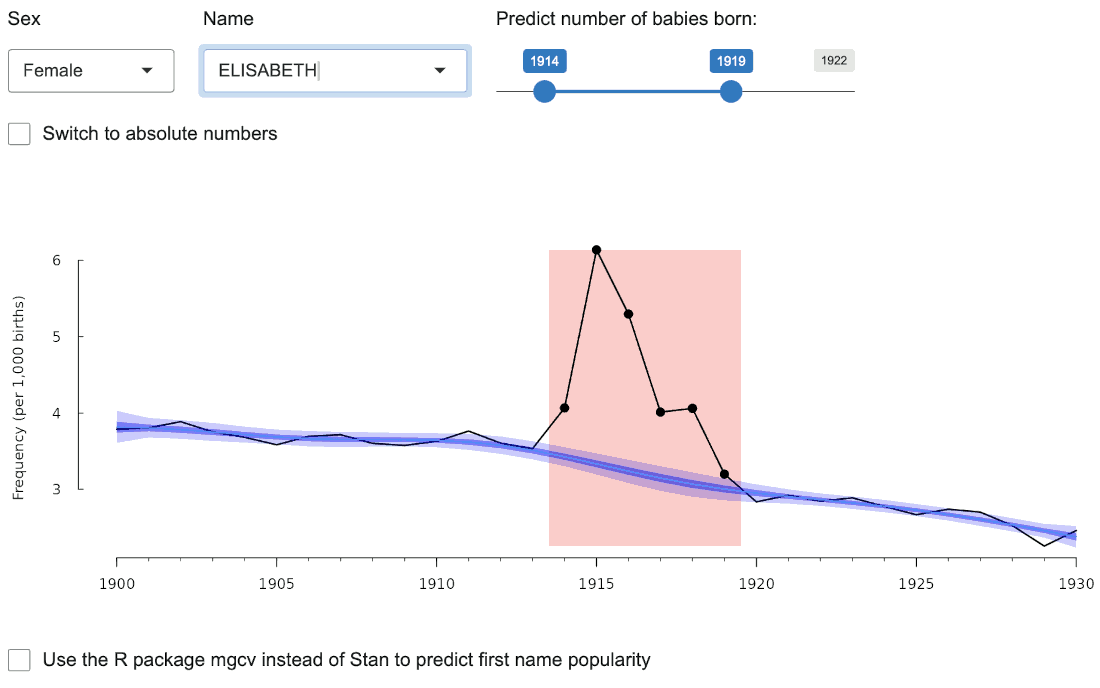
 Parce qu’on peut disposer assez facilement de listes de prénoms, ces listes ont souvent été utilisées pour étudier les réactions des populations à des événements comme des guerres ou des crises diplomatiques. Mais on prend en général quelques prénoms « candidats » et on étudie la variation de leur fréquence parmi les naissances qui ont lieu à proximité de l’événement étudié : le prénom « Philippe » quand Pétain arrive au pouvoir ? le prénom « Adolphe » après 1940 ? le prénom « John » au moment de la Crise de Cuba, etc…
Parce qu’on peut disposer assez facilement de listes de prénoms, ces listes ont souvent été utilisées pour étudier les réactions des populations à des événements comme des guerres ou des crises diplomatiques. Mais on prend en général quelques prénoms « candidats » et on étudie la variation de leur fréquence parmi les naissances qui ont lieu à proximité de l’événement étudié : le prénom « Philippe » quand Pétain arrive au pouvoir ? le prénom « Adolphe » après 1940 ? le prénom « John » au moment de la Crise de Cuba, etc…