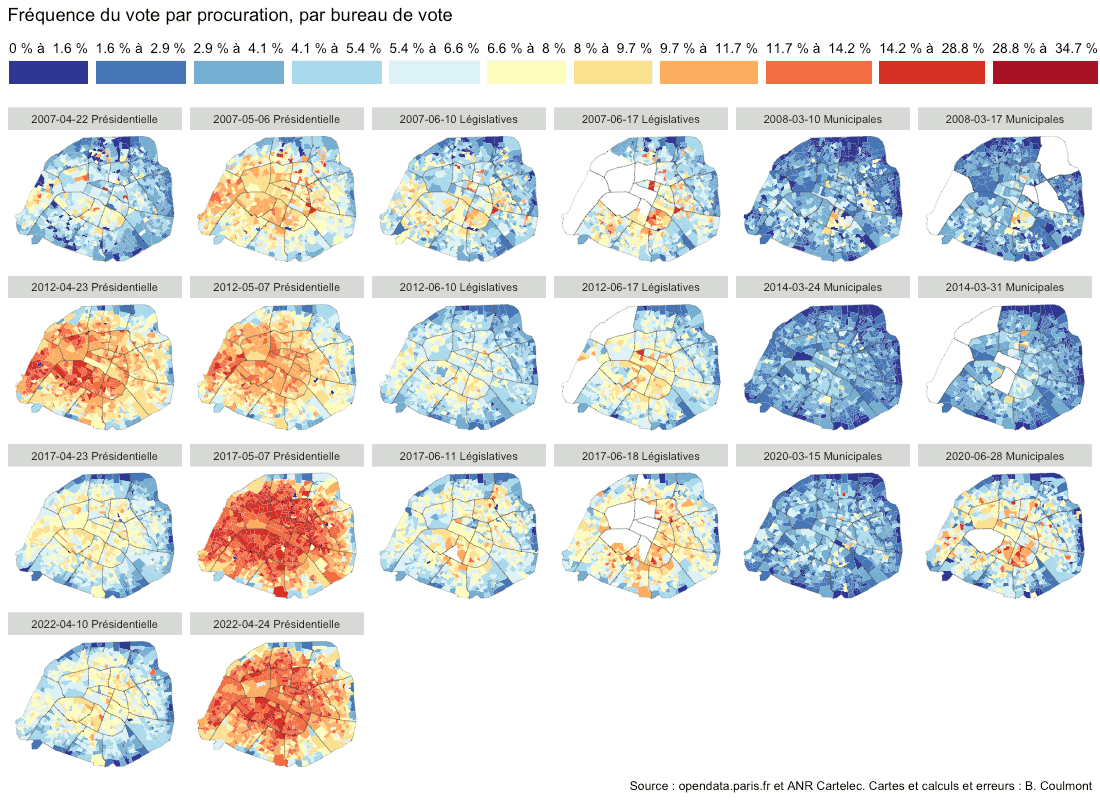
Il y a, en 2022, environ 502 000 élus dans les différents conseils municipaux en France. Le répertoire national des élus est téléchargeable sur data.gouv.fr. Les prénoms les plus fréquents sont Jean, Marie, Philippe, Michel…
Mais ces prénoms sont aussi fréquents dans la population française non élue. Quels sont donc les prénoms qui sont sur-représentés chez les élus ?
Voici le raisonnement que j’ai suivi : j’ai comparé les prénoms des élus avec les prénoms des personnes nées en France, à partir du Fichier des prénoms, de l’Insee. Je vais présenter les résultats sous la forme d’un graphique qui compare la distribution des prénoms dans le Répertoire national des élus avec la distribution du Fichier des prénoms. Voici un graphique explicatif :

Vous remarquerez que les échelles sont logarithmiques.
Première comparaison
Je commence par comparer la population des élus et élues avec la population née en France depuis 1900 à partir du Fichier des prénoms. S’il y a 1,2% des naissances qui sont des naissances de bébés prénommés Zygloub et qu’il y a 2,4% de Zygloub parmi les élus, alors Zygloub est 2 fois plus présent chez les élus que ce qui est attendu (2 = 2,4 / 1,2).
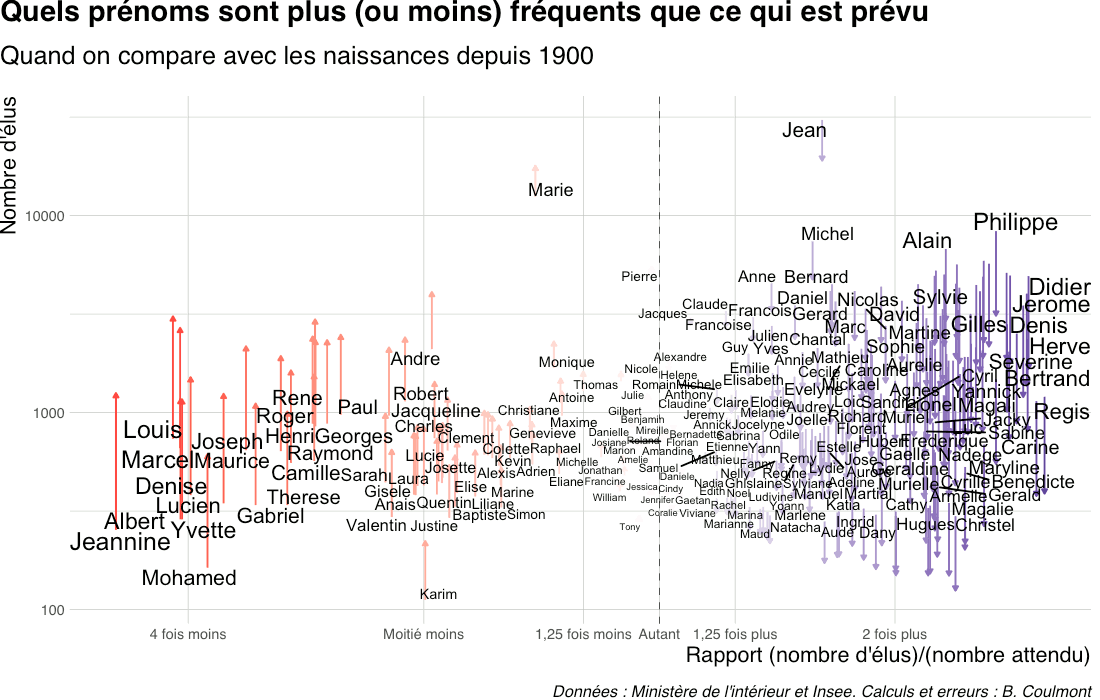
Apparemment, il y a “trop” de Didier et de Régis parmi les élus, et “pas assez” de Jeannine, de Mohamed et de Thérèse. Quatre fois moins de Louis qu’attendu, et trois fois plus d’Hervé.
Mais on a tout de suite un problème : la population des élus municipaux compte moins de femmes que la population française, ce qui va se refléter sur la position des prénoms sur ce graphique. Je vais donc faire une deuxième comparaison, en tenant compte de la part des femmes parmi les élu·e·s.
Deuxième comparaison
Cela ne change pas grand chose, mais on voit des prénoms comme Justine ou Marie se rapprocher d’un rapport d’égalité :
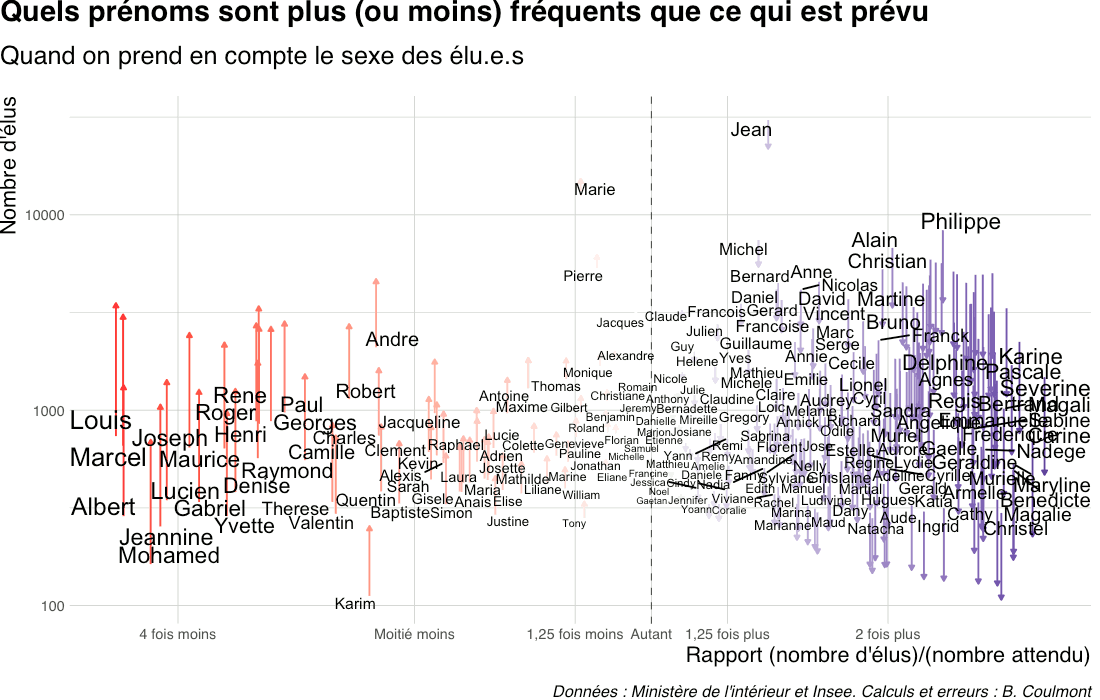
Et de l’autre côté du graphique, les prénoms masculins sur-représentés apparaissent moins sur-représentés (étant donné que les hommes constituent la majorité des élus).
Troisième comparaison
On peut aller plus loin : les élus municipaux sont principalement des élus de toutes petites communes. Et à Paris, par exemple, il y a peu d’élus municipaux par comparaison avec la population. Quand on compare les prénoms de la population à ceux des élus, on peut le faire sur une base départementale : s’il y a peu de Samira en Corrèze, il y aura sans doute peu d’élues nommées Samira (même si, dans le Nord, il va naitre plus de Samira).
Dans le graphique suivant, je contrôle donc par les naissances départementales :

Peu de changements, là aussi. Mais quand même : si les Mohamed étaient quatre fois moins fréquents qu’attendus quand on ne prenait pas en compte les départements, ils ne sont plus que 2,5 fois moins fréquents qu’attendus.
Quatrième comparaison
Il faut donc probablement contrôler par le sexe et le département, comme je le propose ci-dessous :

Bof, non ? Ça ne conduit pas à une modification radicale des sur- et sous-représentations. C’est probablement parce que j’ai oublié que les élus n’avaient pas 110 ans, et qu’ils n’avaient pas 10 ans non plus.
Cinquième comparaison
Il faut donc, bien entendu, contrôler par l’année de naissance. Et cela d’autant plus que les prénoms connaissent souvent une période – plutôt courte – pendant laquelle ils sont beaucoup donnés. Si les Jeannine sont peu présentes parmi les élus, c’est parce qu’elles sont en grande partie déjà décédées.
Dans le graphique suivant, je prend donc en compte la distribution par âge de la population des élus.

Ah, là il y a du changement. Une bonne partie des prénoms se retrouvent à proximité du rapport d’égalité entre le nombre d’élus et le nombre attendu d’élus. Mais ne peut-on pas aussi prendre en compte le sexe et le département ?
Sixième comparaison
Oh que si : dans le dernier graphique, je montre les résultats d’un calcul prenant en compte l’année de naissance, le sexe et le département d’élection des élu·e·s :

La “boule” centrale s’est encore rétrécie : on prévoie assez bien combien il y a aura de Céline élues si l’on connaît la distribution par âge, sexe et départements de la population des élues. Il reste quelques prénoms que ces variables expliquent mal : Bertrand, Armelle, Bénédicte, Etienne, Benoît, Hugues et Hubert se retrouvent trop souvent parmi les élus. Est-ce un signe que ces prénoms sont attachés à des personnes disposant de ressources sociales plus importantes ? De l’autre côté, on trouve des prénoms symétriques : Tony, Kevin, Sabrina, Nadia, Jonathan, Jessica… que l’on devrait retrouver plus souvent chez les élus.
Et Mohamed et Karim : même en tenant compte de l’âge des élus, de leur département d’élection, de leur sexe… il y a “trop peu” de Mohamed et de Karim parmi les élus municipaux. Pour quelles raisons ? Peut-être l’utilisation d’un autre prénom au quotidien et une candidature sous un autre prénom que le prénom de naissance (comme le firent ou le font Marie-Ségolène “Ségolène” Royal, Marion-Anne “Marine” Le Pen et tant d’autres). Peut-être qu’il faudrait prendre en compte une échelle plus fine que le département ? Ou peut-être qu’on trouverait d’autres raisons si on cherchait un peu.
Notes :
- J’ai transformé les prénoms composés : Anne-Marie est Anne, Jean-Philippe est Jean…
- J’ai asciifié les prénoms : ils n’ont plus aucun accent ni cédilles
- C’est un peu stupide de prendre en compte les naissances départementales pour estimer une proportion attendue, comme si les élus étaient nés là où ils sont élus
- Et en plus, avec la fin du département de la Seine en 1968, les codages bizarres de l’Outre-Mer, je ne suis pas certain de ne pas avoir été trop rapide parfois
- J’ai sans doute fait des erreurs, mais si vous voulez les corriger, le code est sur github