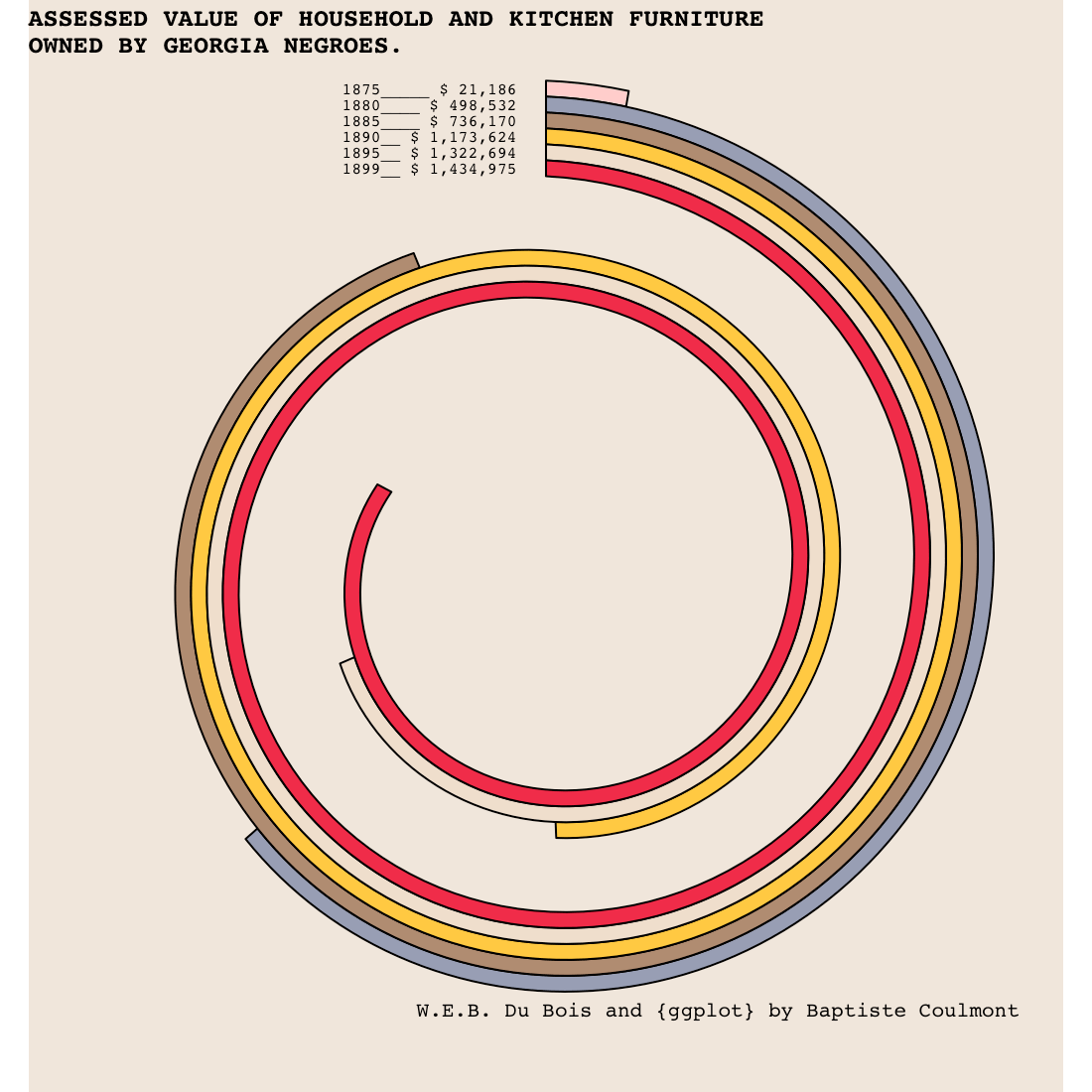
L’identité, dictionnaire encyclopédique (Gallimard, 2020, dir. Jean Gayon) [lien amazon], qui vient d’être publié, propose environ 140 notices, de trinité à épigénétique, dont une dont je suis l’auteur. Chaque notice compte entre deux et neuf renvois vers d’autres notices, et chaque notice reçoit entre zéro et seize renvois. Je vais traiter ces renvois comme des liens entre notices.
L’identité, dictionnaire encyclopédique (Gallimard, 2020, dir. Jean Gayon) [lien amazon], qui vient d’être publié, propose environ 140 notices, de trinité à épigénétique, dont une dont je suis l’auteur. Chaque notice compte entre deux et neuf renvois vers d’autres notices, et chaque notice reçoit entre zéro et seize renvois. Je vais traiter ces renvois comme des liens entre notices.
Il y a, en tout, 750 liens. Dans le graphique suivant, chaque notice est représentée par un point, et s’il y a un renvoi entre deux notices, alors un arc est tracé entre les deux points. La couleur correspond au domaine de la notice (Sociologie, Sciences naturelles…). Le grand nombre de liens et de notices rend le graphique peu lisible.

Toutes les notices sont donc reliées, directement ou indirectement, à toutes les autres (parce que chaque notice comporte des renvois à d’autres : car il existe quelques notices à laquelle aucune autre ne renvoie). La grosse “pelote” de liens montre un travail pluridisciplinaire, une attention au croisement entre disciplines (au moins au niveau des références) : il y aurait facilement pu y avoir deux ou trois “pelotes” fortement connectées en internes mais faiblement connectées aux autres. Or ce n’est pas le cas.
Certains chemins de citation sont assez long : on ne passe pas des sciences naturelles à la littérature en un petit saut. Le plus long relie la Physique quantique aux Troubles de la mémoire : voilà ce qui arrive quand on oublie dans quelle boîte on a mis le chat de Shrödinger.
physique quantique –> lois de la nature –> changement –> developpement (biologie) –> developpement (psychologie) –> double –> copie –> genie –> troubles de la personnalite
Le nombre moyen de citations vers d’autres notices est très proche entre domaines. Si les philosophes avaient autant cité que les Psy, alors ils auraient proposé 18 renvois en plus.
| Philo |
17 |
84 |
4.9 |
| Sc. nat. |
36 |
180 |
5.0 |
| Socio |
30 |
166 |
5.5 |
| Littérature |
24 |
134 |
5.6 |
| Psy |
31 |
185 |
6.0 |
La grosse différence c’est le renvoi vers d’autres domaines. Seulement 28% des renvois en provenance des notices en “Sociologie” sont en direction d’autres notices en “Sociologie”, alors que c’est le cas de 57% des notices de sciences naturelles. Qu’en conclure ? Que les sociologues se pensant comme discipline centrale, ils (et elles) pense que tout le reste leur est annexe (“bon à picorer”) ? Où qu’ils (et elles) sont faiblement disciplinaires et cherchent à légitimer leurs textes par des références à d’autres disciplines? On ne proposera pas de grande conclusion en se basant sur 30 notices.

La pelote n’était pas très lisible : on l’a compris : beaucoup de liens, et des liens qui vont d’une discipline à l’autre.
Mais on pourrait considérer que deux notices sont vraiment en lien quand elles font toutes deux références à l’autre, quand le lien entre elles est mutuel. Dans le graphique suivant, je n’ai donc gardé que les notices « fortement connectées » entre elles.

cliquez pour agrandir
On voit un peu mieux apparaître des branches disciplinaires.
Les notices s’organisent autour de trois cercles tangents. Un premier cercle philosophique Individu – genidentité – changement – principe d’identité – même/autre – ipséité – identité narrative … jusqu’à la personne. De l’autre côté un cercle plutôt sociologique, que l’on va faire commencer par individu – personne – papier d’identité – nom/prénom – nom propre – langue – identité nationale – race – classification et retour au point de départ. Et un dernier cercle « sciences naturelles ».
Au « centre » de ce réseau, les notices individu, personne et identité personnelle. Je mets ici « centre » entre guillemets car une représentation graphique de ce type peut être trompeuse. Il est peut-être préférable de faire appel aux indices de centralité que l’on utilise pour repérer, dans un réseau, les individus les plus centraux.
Imaginons une lectrice qui commencerait à lire le dictionnaire en prenant une notice au hasard et qui chercherait à atteindre le plus rapidement une autre notice, le point de passage le plus fréquemment traversé le long du plus court chemin entre deux autres nœuds est ici la notice “Développement (psychologie)”.

Un autre indice peut nous intéresser, plus simple : le nombre de liens envoyés et reçus, par chaque notice, c’est à dire la centralité « de degré ». Tout en haut, « Race », qui est dans les renvois de 15 notices et qui propose neuf renvois.

« Race » ? Voilà qui est intéressant dans un dictionnaire encyclopédique de l’identité. En tout cas je ne m’y attendais pas.On peut toutefois se dire que ce n’est pas la même chose de recevoir un lien de la notice “Trinité”, qu’aucune autre notice ne cite, ou de la notice “Nom propre”, qui est plus souvent proposée comme renvois, et prendre en compte le nombre de citation reçu par la notice citante pour déterminer la centralité de la notice citée.
Dans ce cas, c’est la notice « Race » qui reçoit encore le score le plus élevé : elle est souvent citée, mais elle est aussi souvent citée par des notices elles aussi souvent citées (par des notices souvent citées…). Voilà qui donne une actualité certaine à ce dictionnaire (et on pourra lire avec profit les réflexions sur la fin de l’analyse de classe ? d’Abdellali Hajjat) ).

Cependant ce premier score est faiblement assuré. Celui de la notice « Individu » est très très proche, et quelques liens en plus ou en moins l’aurait fait passer en première position. J’ai fait le calcul : si l’on enlève 7 citations au hasard, soit 1% du total, et qu’on répète l’opération un millier de fois, alors « individu » se retrouve plus souvent en première position que « race ». Certes : mais c’est cet ouvrage qui existe, pas les 1000 autres ouvrages virtuels qu’on aurait pu écrire.
Dans le graphique suivant, que je propose en conclusion, ne sont indiqués que les titres des notices les plus « centrales » au sens des trois indices précédents.

cliquez pour agrandir
L’Identité, dictionnaire encyclopédique est dans toutes les bonnes librairies : lien librest – lien decitre – lien leslibraires…