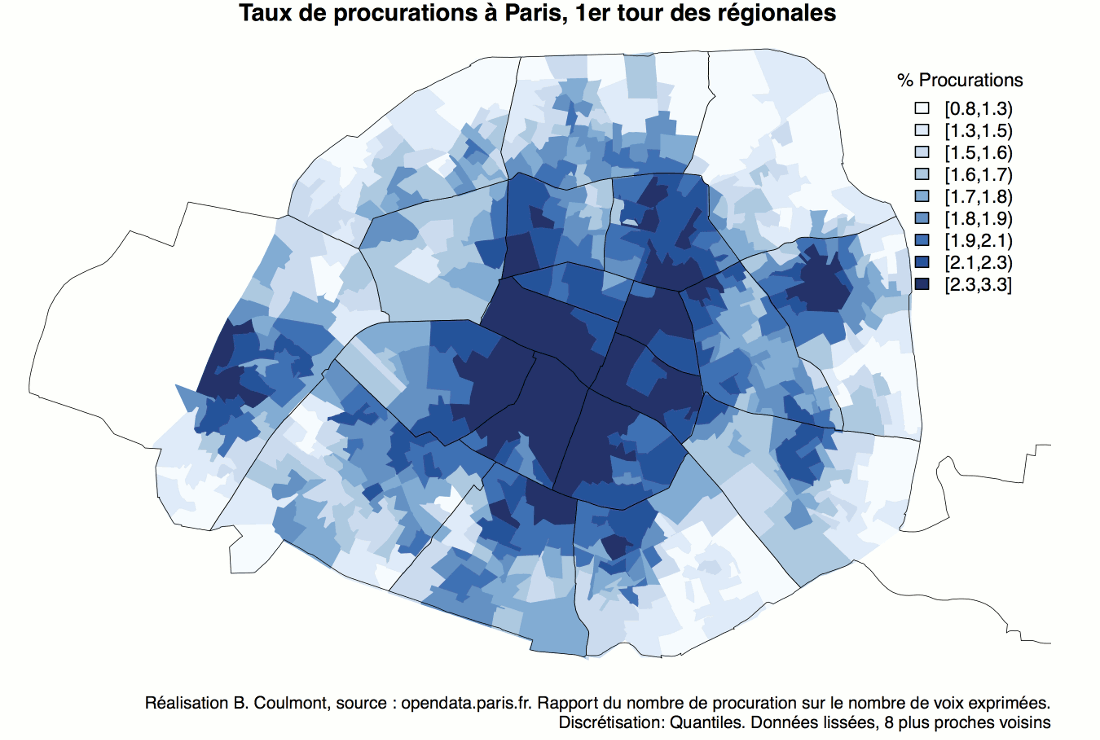
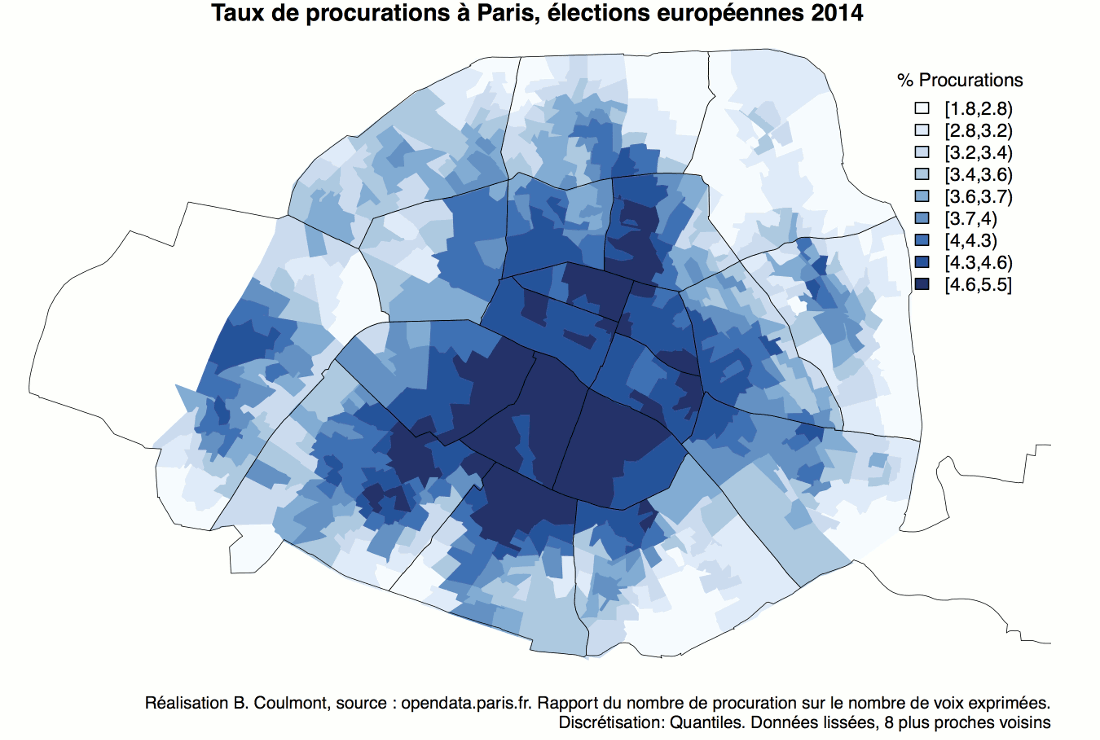
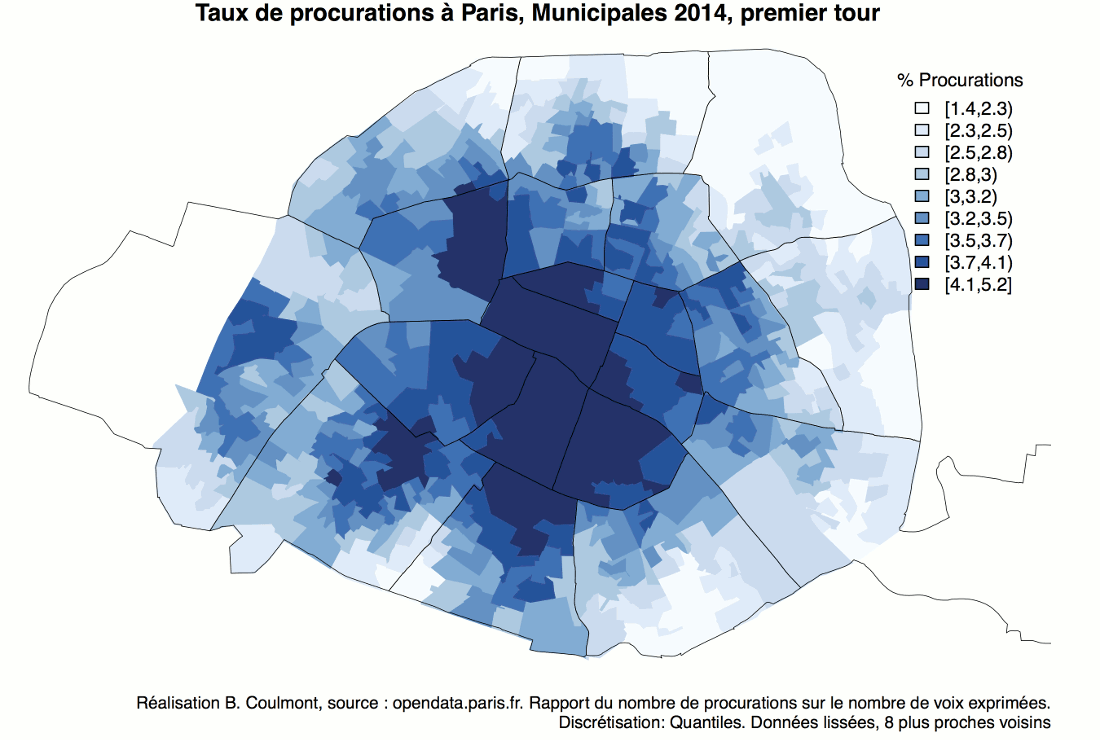
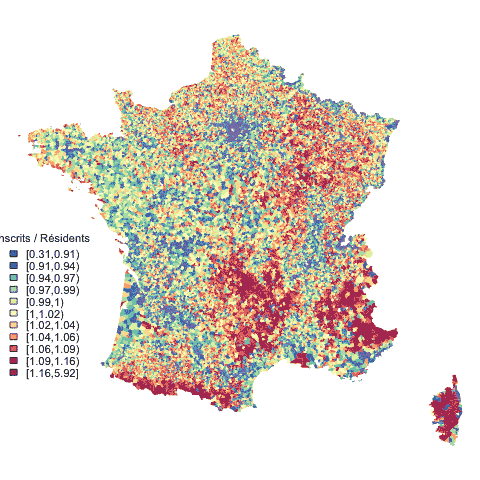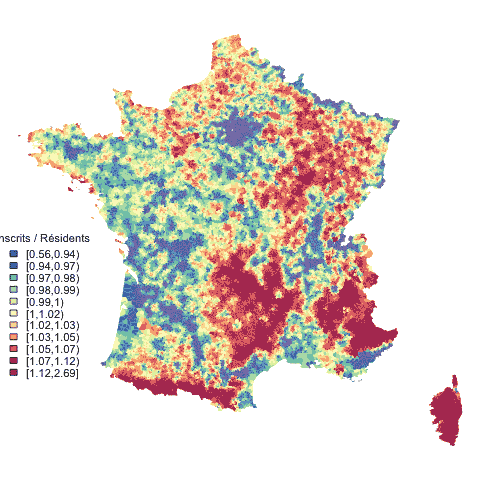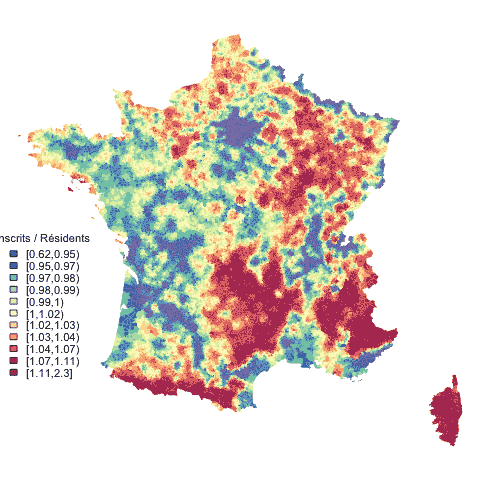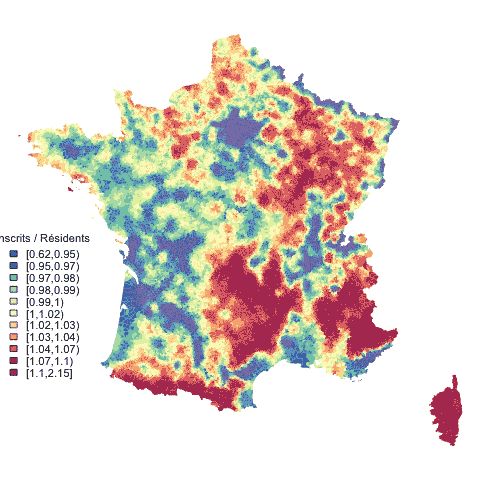
À partir des résultats au premier tour de l’élection présidentielle de 2017, à Paris, on peut tracer cette carte montrant les zones où les différents candidats ont réalisé des scores supérieurs à leur moyenne parisienne.

cliquez pour agrandir
Et voici le code, non commenté. Je commence par repérer où se trouvent les zones de sur-performance (les bureaux de votes). J’extrait du fond de carte parisien les 4 zones distinctes. Je trace ensuite quatre cartes les unes sur les autres.
library(tidyverse)
library(classInt)
library(RColorBrewer)
library(maptools)
library(rgdal)
setwd("~/Dropbox/projets-R/")
# le "shapefile" se trouve sur opendata.paris.fr
paris<-readOGR("../data/2017-listes-paris/secteurs-des-bureaux-de-vote-3/",
"secteurs-des-bureaux-de-vote")
# frontières des arrondissements
parisarr <- readOGR ("../procurations/paris/arrondissements/parisarr.shp", layer="parisarr")
# les résultats électoraux se trouvent sur opendata.paris.fr
df <- read_csv2("~/Dropbox/procurations/paris/paris-2017/resultats_electoraux.csv")
df <- df %>% filter(`date du scrutin`=="2017-04-23") %>%
select(3,4,6,7,8,9,10,12,14,15,16,17) %>%
spread(key=`nom du candidat ou liste`,value=`nombre de voix du candidat ou liste obtenues pour le bureau de vote`) %>%
mutate(numbv=paste(`numero d'arrondissement 01 a 20`,`numero de bureau de vote 000 a 999`,sep="-"))
res <- df %>% group_by(numbv) %>%
summarize(arr=mean(as.numeric(`numero d'arrondissement 01 a 20`)),
prop_macron=100*MACRON/`nombre d'exprimes du bureau de vote`,
prop_lepen=100*`LE PEN`/`nombre d'exprimes du bureau de vote`,
prop_fillon=100*FILLON/`nombre d'exprimes du bureau de vote`,
prop_melenchon=100*(HAMON+`MÉLENCHON`)/`nombre d'exprimes du bureau de vote`) %>%
gather(key=type,value=valeur,-numbv,-arr)
res <- res %>% group_by(type) %>%
mutate(sur_rep=valeur/(mean(valeur)+.2*sd(valeur))) %>% # "la moyenne et un peu plus" (.2 écart type)
filter(sur_rep>1) %>% group_by(numbv) %>%
mutate(keep=type[which.max(sur_rep)],valeur_keep=valeur[which.max(sur_rep)]) # on garde le candidat "le plus au dessus" de sa moyenne
# on ne garde pas les bureaux dupliqués
res <- res[!duplicated(res$numbv),]
# extraction des zones-candidats
macron <- subset(paris,paris$id_bv %in% res$numbv[res$keep=="prop_macron"])
lepen <- subset(paris,paris$id_bv %in% res$numbv[res$keep=="prop_lepen"])
melenchon <- subset(paris,paris$id_bv %in% res$numbv[res$keep=="prop_melenchon"]) # avec le score d'Hamon ajouté
hamon <- subset(paris,paris$id_bv %in% res$numbv[res$keep=="prop_hamon"])
fillon <- subset(paris,paris$id_bv %in% res$numbv[res$keep=="prop_fillon"])
png("~/Desktop/parissur_rep.png",width=1100,height=800,res=150)
par(mar=c(1,0,1,1))
plot(paris) # on commence par "tracer" Paris
m<-match(macron$id_bv,res$numbv)
plotvar<-res$valeur_keep
nclr <- 3
plotclr <- brewer.pal(nclr,"Greens")
class <- classIntervals(plotvar[m], nclr, style="fisher",dataPrecision=1)
colcode <- findColours(class, plotclr)
plot(macron,col=colcode,border=colcode,add=T)
m<-match(fillon$id_bv,res$numbv)
plotvar<-res$valeur_keep
nclr <- 3
plotclr <- brewer.pal(nclr,"Blues")
class <- classIntervals(plotvar[m], nclr, style="fisher",dataPrecision=1)
colcode <- findColours(class, plotclr)
plot(fillon,col=colcode,border=colcode,add=T)
m<-match(melenchon$id_bv,res$numbv)
plotvar<-res$valeur_keep
nclr <- 3
plotclr <- brewer.pal(nclr,"Reds")
class <- classIntervals(plotvar[m], nclr, style="fisher",dataPrecision=1)
colcode <- findColours(class, plotclr)
plot(melenchon,col=colcode,border=colcode,add=T)
m<-match(lepen$id_bv,res$numbv)
plotvar<-res$valeur_keep
nclr <- 3
plotclr <- brewer.pal(nclr,"Purples")
class <- classIntervals(plotvar[m], nclr, style="fisher",dataPrecision=1)
colcode <- findColours(class, plotclr)
plot(lepen,col=colcode,border=colcode,add=T)
plot(parisarr,add=T,lwd=.1) # on ajoute les frontières des arrondissements
legend(2.232, 48.91,legend=c("Hamon/Melenchon","Le Pen","Fillon","Macron"), fill=c("red","purple","deepskyblue","chartreuse3"), cex=1, bty="n",title="")
title(main="Zone de sur-performance des candidats. Paris. Présidentielles 2017.")
title(sub="Fond : opendata.paris.fr | données : Ville de Paris | Cartographie : B. Coulmont\nZones où les candidats font mieux que leur moyenne",line=-.5,cex.sub=.8)
dev.off()
Et, en bonus, le code, amélioré par Christophe P. :
library(tidyverse)
library(classInt)
library(RColorBrewer)
library(maptools)
library(rgdal)
rep_data_secteurs < - 'DATA/secteurs-des-bureaux-de-vote'
# "../data/2017-listes-paris/secteurs-des-bureaux-de-vote-3/"
setwd("~/Dropbox/projets-R/")
# le "shapefile" se trouve sur opendata.paris.fr
paris<-readOGR(rep_data_secteurs,
"secteurs-des-bureaux-de-vote")
# frontières des arrondissements
parisarr <- readOGR ("../procurations/paris/arrondissements/parisarr.shp", layer="parisarr")
# les résultats électoraux se trouvent sur opendata.paris.fr
df <- read_csv2("~/Dropbox/procurations/paris/paris-2017/resultats_electoraux.csv")
df <- df %>% filter(`date du scrutin`=="2017-04-23") %>%
select(3,4,6,7,8,9,10,12,14,15,16,17) %>%
spread(key=`nom du candidat ou liste`,value=`nombre de voix du candidat ou liste obtenues pour le bureau de vote`) %>%
mutate(numbv=paste(`numero d'arrondissement 01 a 20`,`numero de bureau de vote 000 a 999`,sep="-"))
res < - df %>% group_by(numbv) %>%
summarize(arr=mean(as.numeric(`numero d'arrondissement 01 a 20`)),
prop_macron=100*MACRON/`nombre d'exprimes du bureau de vote`,
prop_lepen=100*`LE PEN`/`nombre d'exprimes du bureau de vote`,
prop_fillon=100*FILLON/`nombre d'exprimes du bureau de vote`,
prop_melenchon=100*(HAMON+`MÉLENCHON`)/`nombre d'exprimes du bureau de vote`) %>%
gather(key=type,value=valeur,-numbv,-arr)
res < - res %>% group_by(type) %>%
mutate(sur_rep=valeur/(mean(valeur)+.2*sd(valeur))) %>% # "la moyenne et un peu plus" (.2 écart type)
filter(sur_rep>1) %>% group_by(numbv) %>%
mutate(keep=type[which.max(sur_rep)],valeur_keep=valeur[which.max(sur_rep)]) # on garde le candidat "le plus au dessus" de sa moyenne
# on ne garde pas les bureaux dupliqués
res < - res[!duplicated(res$numbv),]
# extraction des zones-candidats
extract_zone <- function (name)
{
field <- paste0("prop_", name)
return(subset(paris,paris$id_bv %in% res$numbv[res$keep==field]))
}
macron <- extract_zone('macron')
lepen <- extract_zone('lepen')
melenchon <- extract_zone('melenchon') # avec le score d'Hamon ajouté
hamon <- extract_zone('hamon')
fillon <- extract_zone('fillon')
png("~/Desktop/parissur_rep.png",width=1100,height=800,res=150)
par(mar=c(1,0,1,1))
plot(paris) # on commence par "tracer" Paris
plot_candidate <- function (cand, color)
{
m<-match(cand$id_bv,res$numbv)
plotvar<-res$valeur_keep
nclr <- 3
plotclr <- brewer.pal(nclr, color)
class <- classIntervals(plotvar[m], nclr, style="fisher",dataPrecision=1)
colcode <- findColours(class, plotclr)
plot(cand,col=colcode,border=colcode,add=T)
}
plot_candidate(macron, "Greens")
plot_candidate(fillon, "Blues")
plot_candidate(melenchon, "Reds")
plot_candidate(lepen, "Purples")
plot(parisarr,add=T,lwd=.1) # on ajoute les frontières des arrondissements
legend(2.232, 48.91,legend=c("Hamon/Melenchon","Le Pen","Fillon","Macron"), fill=c("red","purple","deepskyblue","chartreuse3"), cex=1, bty="n",title="")
title(main="Zone de sur-performance des candidats. Paris. Présidentielles 2017.")
title(sub="Fond : opendata.paris.fr | données : Ville de Paris | Cartographie : B. Coulmont\nZones où les candidats font mieux que leur moyenne",line=-.5,cex.sub=.8)
dev.off()