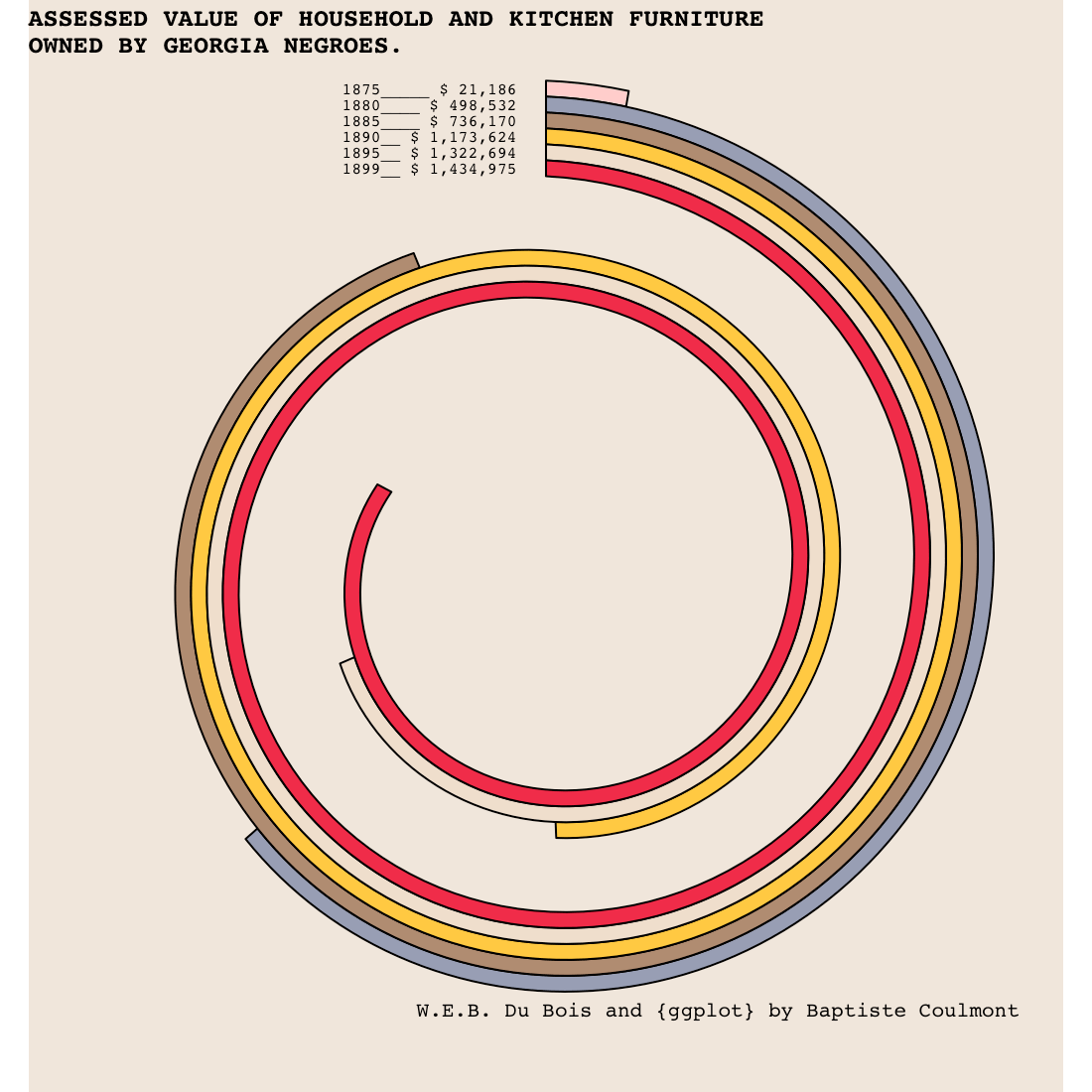
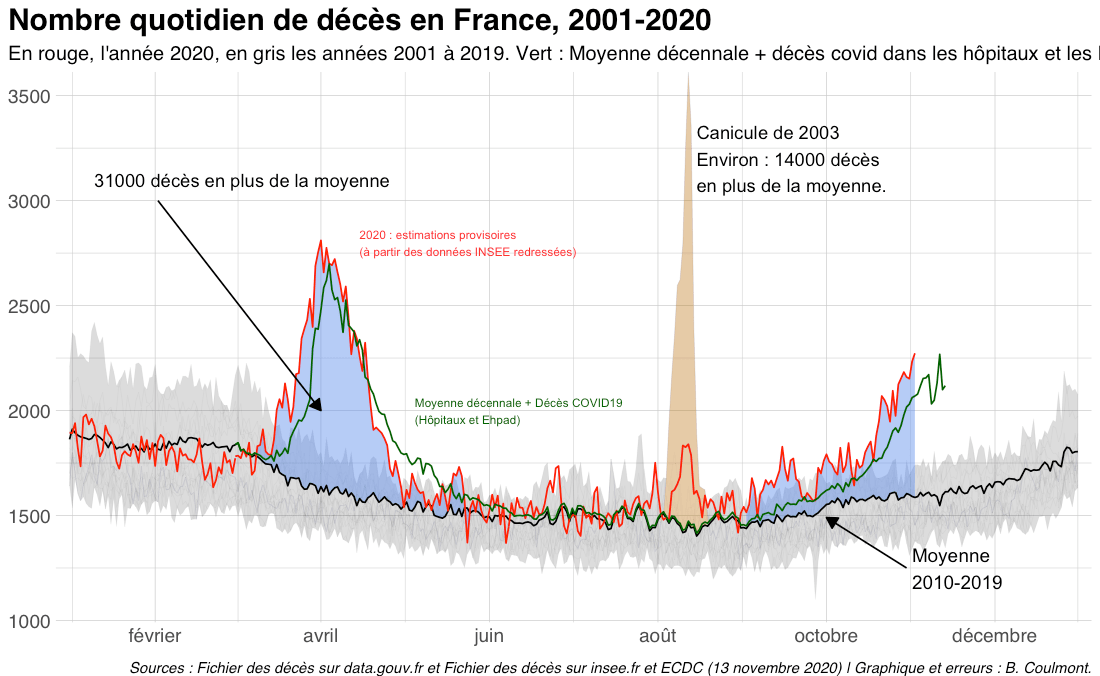
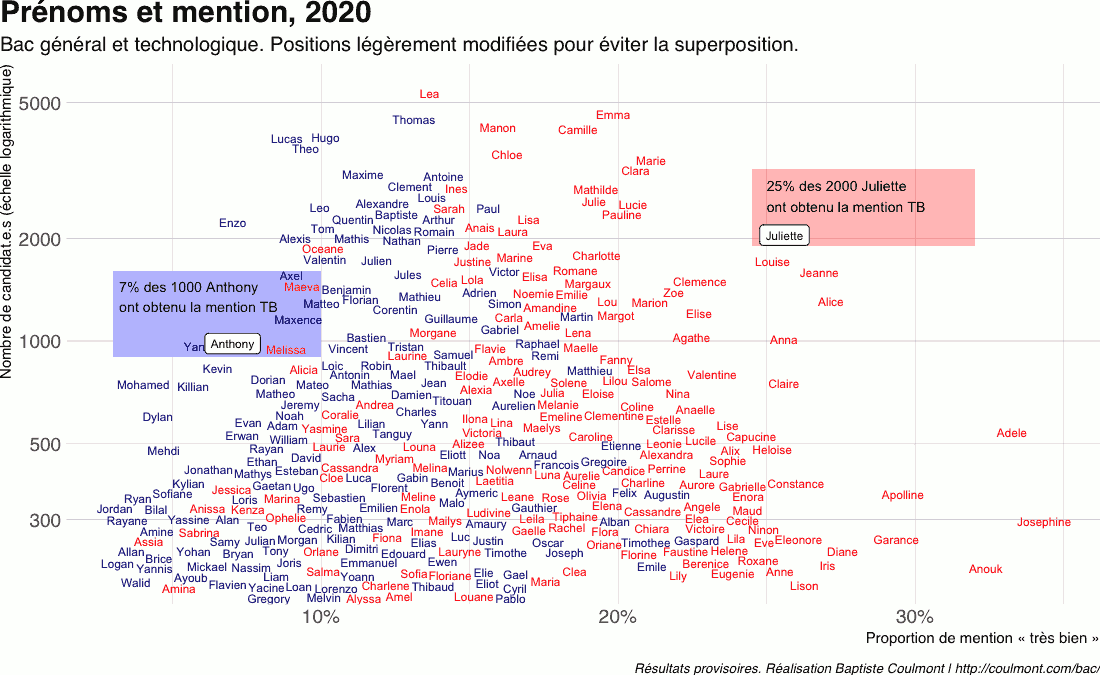
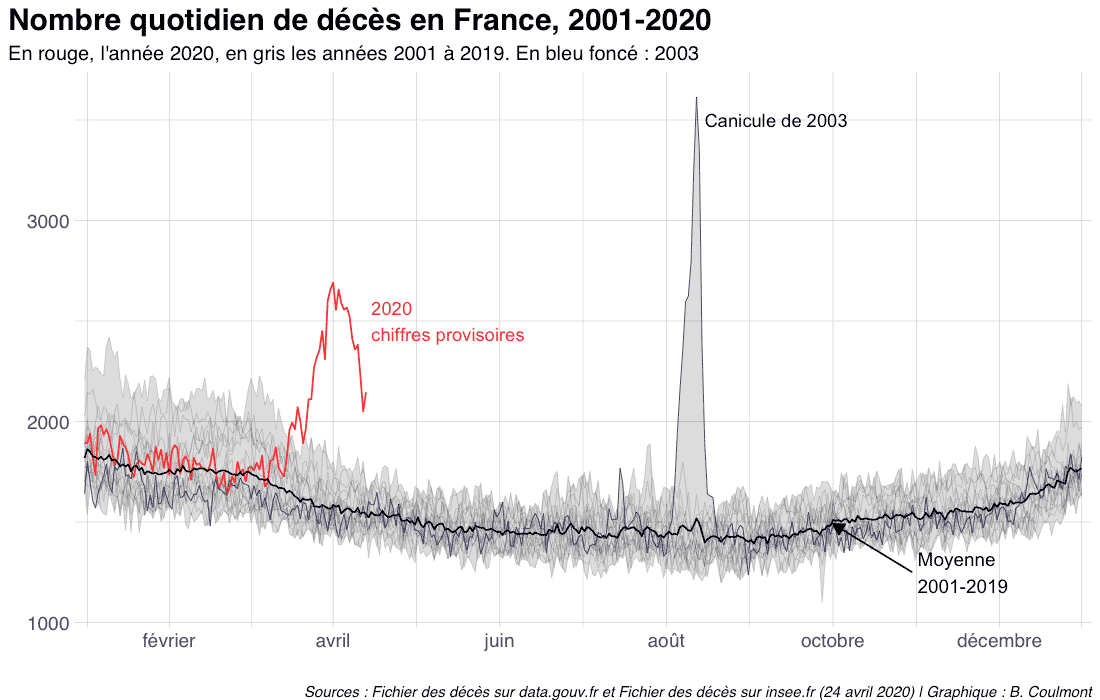
Mon père, ce héros ? (ou Son père, mon héros)
Le Journal of Interdisciplinary History vient de publier un article (co-écrit avec Nicolas Todd, du Centre Roland Mousnier, CNRS) sur la transmission des prénoms pendant la Première Guerre mondiale.
Ce que nous avons cherché à expliquer, c’est, essentiellement, ce graphique :
![]()
Entre 1905 et le 1er août 1914, mois après mois, semaine après semaine, 12% des garçons environ reçoivent en premier prénom le premier prénom de leur père. D’après les données fournies par geneanet, c’est très stable mais à la baisse, à mesure que les parents cessent de transmettre un prénom et préfèrent, pour leurs enfants, des prénoms nouveaux. Le graphique précédent se concentre sur le taux hebdomadaire entre janvier 1913 et mars 1915, pour les garçons (on observerait la même chose pour les filles).
Mais dès la semaine du 3 août 1914, après la déclaration de guerre et la mobilisation générale du 1er août 1914, le taux de transmission passe à 17 ou 18%. On observerait des choses similaires, mais avec des proportions plus élevées, si l’on s’était intéressé à « la transmission d’un des prénoms du père à son fils » (par exemple le 3e prénom du père transmis en première position).
Toute la question est de savoir à quoi est due cette augmentation rapide ? On pourrait croire à de l’imitation, mais c’est trop rapide, le basculement se fait en quelques heures à peine, et qui donc les mères imiteraient ? Ce n’est pas non plus — en tout cas pas au cours des trois premières semaines d’août — lié aux décès des pères. Enfin ce n’est pas — à elle seule — la situation de guerre et la perturbation générale de la « division sociale du travail » qui conduit à cette hausse. Car tout redevient normal (au niveau des prénoms) en mai 1915 alors que tout reste en guerre.
![]()
Pourquoi donc, neuf mois environ après le début du conflit, ce taux de transmission revient au niveau initial ? (Indice : neuf mois).
Dans l’article, nous avançons l’idée selon laquelle la sur-transmission est liée au niveau de risque encouru par le père : ce sont les pères susceptibles de décéder dont le prénom est transmis. Ainsi les pères qui décèderont après la naissance de leur enfant, pendant la guerre, voient leur prénom plus transmis que les autres pères. Et les pères qui décèdent *avant* la naissance de leur enfant (les pères dont le risque est avéré, donc) « voient » très souvent leur prénom transmis.
On s’intéresse aussi à l’héroïsation, mais en se penchant sur la transmission du prénom des oncles. En effet, le créneau de transmission, pour les pères, est limité : leurs enfants ne peuvent naître plus de neuf mois après son décès. Ce n’est pas le cas des oncles : cinq ou six ans après leur décès, leur prénom peut toujours être transmis. Et la surtransmission du prénom des oncles décédés pendant la guerre dure longtemps, jusqu’au milieu des années vingt.
Pour en savoir plus, vous pouvez lire l’article “Naming for Kin during World War I: Baby Names as Markers for War”, mais aussi regarder la capsule vidéo sur youtube, ou consulter le code de déduplication utilisé pour cette enquête (et posté sur github). Une page spécifique consacré à “Naming for Kin” contient d’autres informations.