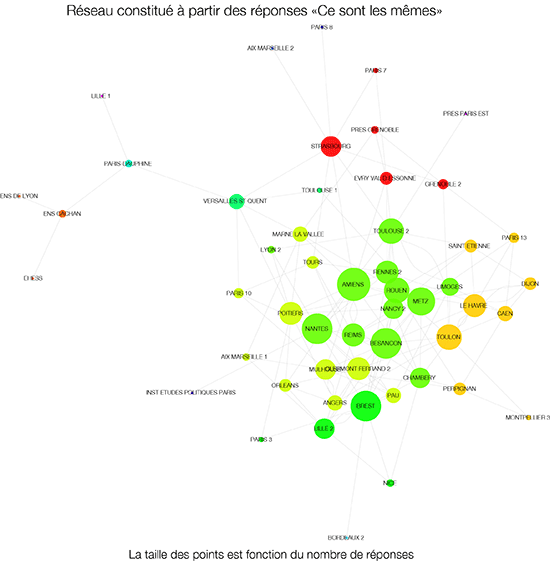
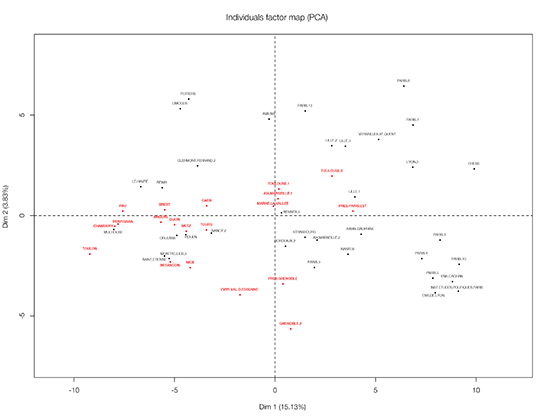
Dis-moi, combien de prénoms as-tu ?
L’on sait peu de choses sur les seconds, troisièmes… et parfois quatrièmes, cinquièmes et sixièmes prénoms. Ce sont des prénoms invisibles dans la vie quotidienne. « Bonjour, je m’appelle Marie, Adélaïde, Charlotte, Garance, Domitille, Sixtine d’Aniel de la Rochefoucault… »
Et dans la plupart des cas, les données statistiques disponibles ne recueillent pas ces prénoms fantômes. Il en va différemment sur les listes électorales, où noms et prénoms permettent l’indexation d’une personne à une carte d’identité. Il est ainsi possible de repérer l’évolution, dans le temps, du nombre moyen de prénoms des personnes inscrites sur les listes électorales.
Sur le graphique suivant, j’ai distingué trois groupes principaux (et distingué, dans ces groupes, les hommes des femmes). Premier groupe, les électeurs nés à l’étranger. Le groupe du milieu, l’ensemble des inscrits. Le groupe du haut les électeurs ayant un nom de famille à particule [la particule semble être un indicateur intéressant].

Les deux groupes “électeurs nés à l’étranger” et “électeurs à particule” se distinguent fortement : les électeurs nés à l’étranger ont en moyenne moins de deux prénoms. Les électeurs à particule en moyenne plus de deux prénoms, voire trois pour les plus jeunes. Alors qu’une particule rallonge déjà le nom de famille moyen, les parents à particule choisissent des formules prénominales plus longues [ce qui complexifie le théorème de Bérurier mentionné par Marie-Anne Paveau]. Manière d’égaliser les deux côtés de la balance onomastique?
Si hommes et femmes né°e°s à l’étranger se ressemblent sous le rapport du nombre de prénom, il n’en va pas de même pour les électeurs à particule, ni, dans une moindre mesure, pour l’ensemble des inscrits : les femmes ont en moyenne moins de prénoms que les hommes. Elles sont peut-être privées d’un capital onomastique (les prénoms des ancêtres, transmis aux hommes de préférence ?)…
Une première lecture de ce graphique insisterait ensuite sur l’augmentation régulière du nombre moyen de prénoms des électeurs.
Mais attention :
- il est probable, très probable, que les jeunes inscrits n’ont pas les mêmes caractéristiques sociales que les inscrits plus âgés (la mal-inscription touchant tendanciellement certaines personnes plutôt que d’autres), et si le nombre de prénom varie en tendance avec l’origine sociale, alors on repère ici les conséquences graphiques d’un effet de sélection
- l’augmentation du nombre de prénoms est peut-être due à des changements administratifs-informatiques dans l’enregistrement des personnes qui se sont inscrites récemment : ceux qui se sont inscrits dans les années 1990 ne pouvaient, peut-être, qu’inscrire deux ou trois prénoms, alors que ceux qui se sont inscrits dans les années 1990-2000 ont eu la possibilité d’inscrire tous leurs prénoms… Cela pourrait expliquer en partie le “saut” visible pour les électeurs nés vers 1980.





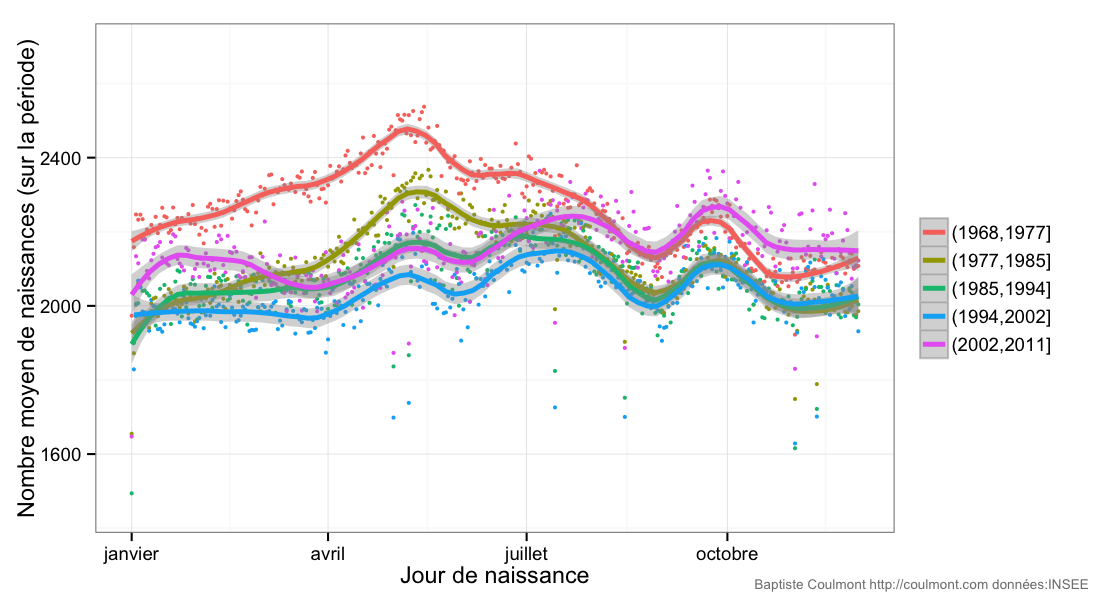
 La chose est connue par de nombreux travaux, mais je voulais continuer mon exploration des rythmes sociaux.
La chose est connue par de nombreux travaux, mais je voulais continuer mon exploration des rythmes sociaux.